Bedrock était présent lors de la Conférence HAProxy qui se déroulait à Paris en novembre 2022 : en tant que speaker, avec la présentation de Vincent Gallissot, mais aussi en tant que spectateur. Cet article relate les points forts qui nous ont marqués.
La présentation de Vincent Gallissot, Lead Cloud Architect chez Bedrock, mettait en valeur l’usage d’HAProxy en tant que brique essentielle de notre infrastructure. Chez Bedrock, nous développons et maintenons une plateforme de streaming qui a été migrée dans le Cloud en 2019. Cette présentation était grandement inspirée de l’article intitulé “Scaling Bedrock video delivery to 50 million users”, dans lequel vous trouverez pléthore d’informations concernant nos utilisations d’HAProxy.

Sommaire
- Ce que des millions de requêtes par seconde signifient en termes de coût et d’économie d’énergie
- Un outil pour les gouverner tous
- Vous reprendrez bien un peu de pétaoctets?
Ce que des millions de requêtes par seconde signifient en termes de coût et d’économie d’énergie.
La keynote d’ouverture avait pour orateur Willy Tarreau, le Lead Developer d’HAProxy.
Au travers d’une démonstration concrète mélangeant software et hardware, l’objectif était de :
- transmettre l’idée qu’ajouter une brique logicielle dans un système ne le dégrade pas pour autant, bien au contraire
- sensibiliser l’audience quant à la consommation d’énergie de nos systèmes
Contexte technique et premières améliorations
Pour ce premier cas d’étude, Willy Tarreau nous présente le cas d’un service de vente en ligne.
La stack technique est composée de PHP / pgSQL (NodeJS + Symfony) et les images sont stockées en base de données. C’est cette architecture qui sera mise à l’épreuve lors des tests de charge à venir.
Dans un premier temps, plusieurs améliorations (sans HAProxy) sont proposées. Il peut s’agir d’un simple rappel, voir d’un pro-tip d’architecture pour les plus novices : Les images en base de données, c’est une mauvaise idée.
En les déplaçant vers un CDN, le système peut rapidement et simplement doubler ses performances, la base de données étant un goulot d’étranglement. La taille des pages peut être optimisée via l’activation de l’option http “gzip”. Les informations de sessions sont elles aussi enregistrées en base de données. Afin d’améliorer les performances, il est possible d’ajouter du caching via des outils tels que Memcache.
Suite à cela, une première amélioration d’architecture serait d’ajouter un NLB (Network Load Balancer) en amont du système qui distribuerait les requêtes entrantes vers plusieurs unités de calculs.
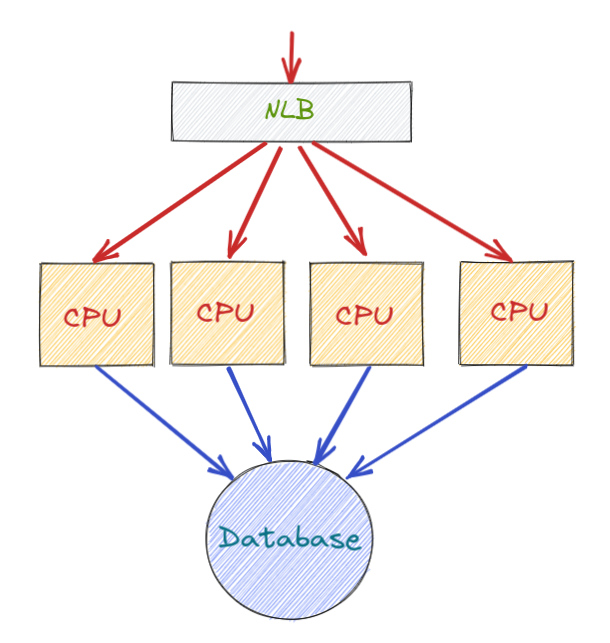
Schéma d’architecture, première version
Dans le cas présent, les requêtes entrantes sont distribuées de façon aléatoire entre les différentes unités de traitement. Chacun de ces backends se connectant à la même et unique base de données.
Le benchmark ci-dessous (efficacité, au sens nombre de requêtes traitées en fonction du nombre d’unités de calcul), ne montre pas une croissance linéaire. Il s’agit d’une courbe tendant vers une pente nulle (voir négative pour les plus grosses architectures).
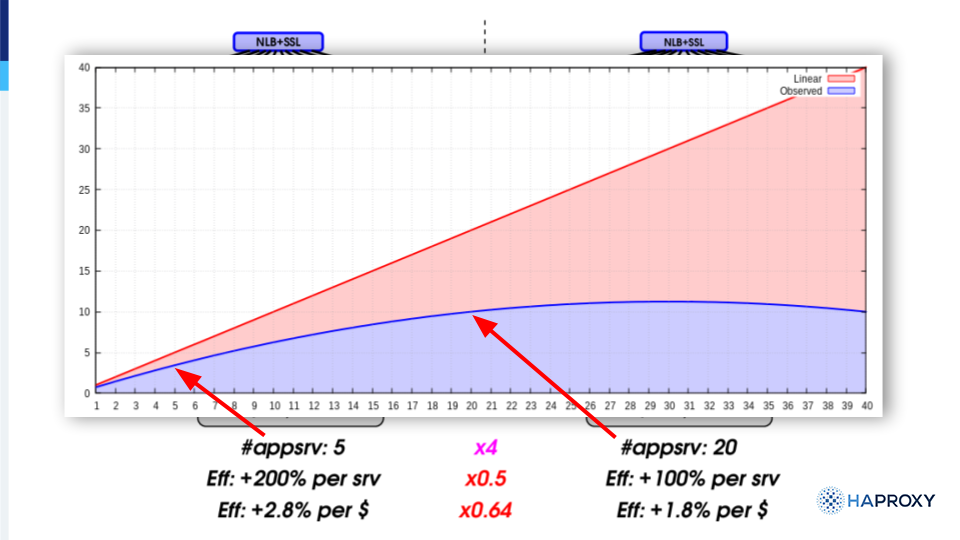
Graphique représentant l’efficacité du système en fonction du nombre de backends
Comment expliquer que cette architecture ne scale pas linéairement ?
Malgré les améliorations apportées pour les sessions grâce au cache, il subsiste encore un problème.
Le NLB est un composant qui ne fait que répartir la charge sans tenir compte de l’historique des requêtes. En effet, celui-ci va distribuer la charge d’entrée aléatoirement vers les backends.
Chaque backend reçoit des requêtes provenant de n’importe quel utilisateur impliquant alors un cache-miss très élevé : l’utilisateur est rarement trouvé dans le cache, ce qui génère une requête supplémentaire en base de données et dégrade les performances en plus de consommer inutilement des ressources.
Et si nous ajoutons HAProxy à notre système ?
C’est ici qu’entre en jeu HAProxy en remplaçant le NLB. Pour cela, pas besoin d’un foudre de guerre en termes de ressources.
Les tests ont été effectués sur une machine ARM Breadbee cadencée à 1 GHz et possédant 64 Mo de RAM. Nous verrons également par la suite qu’on pourrait même se passer d’une machine supplémentaire.
Le but d’HAProxy est de spécialiser les caches des backends et plus globalement de forcer les sessions utilisateurs vers les mêmes backends.
Pour cela, HAProxy effectue une inspection de la couche 7 du trafic et renvoie toutes les requêtes d’un même utilisateur sur une même machine en réduisant ainsi les cache-miss aux seuls cas des nouveaux clients se connectant à la plateforme. Ainsi, le nombre d’appels à la base de données pour récupérer les informations de session est drastiquement réduit, la majorité d’entre elles étant stockées en cache.
Autre fonctionnalité de taille : HAProxy limite le nombre de requêtes faites en parallèle sur un même backend, ce qui limite les locks de processus et les temps d’attente. Ceci a pour conséquence directe de réduire la consommation CPU.
Ces deux améliorations permettent à l’application de scaler de façon beaucoup plus linéaire, tout en réduisant les consommations CPU et énergétiques inutiles. Globalement, les performances initiales sont largement dépassées avec deux fois moins de backends.
A partir de quand est-il intéressant de franchir le pas ?
Maintenant que les bénéfices d’HAProxy ont été présentés, la prochaine étape est de se demander : quand est-ce qu’on se lance ? La question est considérée en termes de performance, mais aussi sous un angle pécunier.
Si HAProxy peut être intégré sans augmenter les coûts du système, c’est encore mieux.
Ajouter HAProxy dans un système composé d’un seul backend n’apporte pas de bénéfice : il n’y a pas de load-balancing possible. Avec deux backends, si on divise le besoin de processing par deux, nous n’avons plus qu’un seul backend et donc pas de load-balancing possible.
C’est en fait à partir de 4 backends que l’ajout d’un HAProxy en entrée devient intéressant :
- en retirant 2 serveurs de nos backends en conservant une puissance équivalente (cf les tests ci-dessus)
- et en recyclant un des deux backends retirés en hôte pour HAProxy En fin de compte, pour une même puissance de traitement, un backend est retiré ce qui permet de réduire les coûts de fonctionnement. Ce principe s’applique également sur un grand nombre de backends.
C’est là que prend tout son sens l’expression qui avait été utilisée pour conclure cette keynote : “HAProxy is a free software running on free hardware”.
Chez Bedrock, nous appliquons aussi ces différentes techniques de Consistent Hashing en entrée de notre CDN vidéo. Nos caches vidéos sont spécialisés et chaque utilisateur est redirigé vers un unique backend lors de la lecture d’une vidéo.
Pour en savoir plus, vous pouvez consulter notre article au sujet du Consistent Hashing.
Un outil pour les gouverner tous
Dans notre activité en informatique, nous sommes amenés à délivrer de plus en plus rapidement des applications, des mises à jour, etc… Nous avons donc adopté la philosophie DevOps et tout un panel d’outils autour de celle-ci afin de sécuriser, monitorer et automatiser chaque étape de nos pipelines de livraison.
Le cas de figure du load balancing est intéressant dans ce type d’organisation, il est essentiel d’exposer de nouvelles applications sur les environnements de production mais étant donné que la maîtrise de cet outil requiert une compréhension du réseau, la responsabilité incombe souvent à l’équipe Ops de le gérer.
Vous souhaitez mieux gérer votre flotte HAProxy ?
Anjelko Iharos, directeur de l’ingénierie à HAProxy Technologies nous a présenté leur nouvel outil d’automatisation : HAProxy Fusion Control Plane, packagé dans la version entreprise de HAProxy.
Celui-ci va amener une nouvelle interface enrichie afin de gérer toutes les instances HAProxy et les outils gravitant autour de ces dernières.
On peut citer :
- La possibilité pour les développeurs de router eux-même leurs applications sans avoir besoin d’un Ops dans leurs pipelines de CI via l’API Fusion.
- Gérer les WAF de HAProxy de manière centralisée et répercuter cette configuration sur un ensemble de clusters/instances.
- Permettre aux Ops de gérer la structure de leurs load balancers, ajouter de nouvelles instances, gérer les certificats SSL, le tuning des performances depuis un seul point d’entrée.
Est-ce résilient ?
Fusion Control Plane est livré avec tout un set de features intéressantes pour assurer sa maintenabilité et sa résilience :
- Une pleine observabilité avec une application unifiée de récupération de logs, métriques et rapports dans la même interface. L’export de ces data est possible, notamment pour les transposer dans un dashboard tiers (Grafana, par exemple).
- Un système de RBAC permettant de mieux gérer les périmètres de chacune des équipes dans le control plane.
- La gestion centralisée de la configuration, la validation des configurations et le bot management. La partie WAF est packagée avec OWASP (communauté publiant des recommandations pour la sécurisation des applications web) ModSecurity Core Rule Set (CRS) pour la détection des vulnérabilités. Dans le cadre d’un cluster un système de failover automatique avec auto-élection du leader (à la manière de GOSSIP avec Consul).
Une vue de l’avenir ?
Aujourd’hui, Fusion Control Plane limite son scope à HAProxy Entreprise et Community Edition, les IngressController ne sont pour le moment pas encore supportés.
Il n’est pas encore pleinement compatible avec les features offertes par AWS (Gestion des ASG et de Route53) mais c’est en cours de développement chez HAProxy Technologies.
Le produit semble prometteur et intéressant. Les possibilités qu’il nous offre pour laisser la main aux développeurs sur la mise en place de routes vers leurs applications côté on-premise est vraiment un gros plus, mais il nous manque pour le moment le support de l’IngressController HAProxy utilisé sur nos cluster Kubernetes, ce qui nous empêche d’en profiter au maximum.
Vous reprendrez bien un peu de pétaoctets ?
Chez Bedrock, un élément central de notre métier est de fournir de la vidéo à nos utilisateurs. (Incroyable pour une boite qui fait de la VOD hein? 😀).
Pour ce faire nous avons nos propres serveurs CDN hébergés sur Paris, en complément des CDN publics comme Cloudfront ou Fastly. Cette année nous avons servis plusieurs centaines de PB de données via nos serveurs et nous espérons pouvoir au moins doubler ce trafic l’année prochaine !
Notre architecture CDN est constituée d’un logiciel appelé LBCDN qui “load-balance” la charge sur les CDN, on-prem et publics, en redirigeant un utilisateur vers un serveur CDN spécifique.
Nos serveurs en eux-mêmes sont basés sur Nginx avec une configuration assez simple en direct IO sur de gros SSD.
La HAproxy conf 2022 nous a pas mal inspirés pour répondre à nos problématiques avec ces deux conférences :
- Boost your web apps with HAProxy and Varnish, by Jérémy Lecour CTO of Evolix:Video
- Was That really HAProxy, by Ricardo Nabinger Sanchez performance engineer at Taghos: Video
Ces deux présentations font état d’une architecture sur les CDN intéressante où HAProxy est utilisé pour mettre “en sandwich” l’outil (ou les outils) faisant fonction de CDN. L’architecture présentée semble permettre une configuration bien plus fine que ce que nous avons actuellement avec seulement Nginx.
Par exemple, sur nos CDN on-prem nous devons aujourd’hui utiliser une astuce pour que Nginx puisse dynamiquement aller résoudre le nom de domaine du backend sur lequel il source ses fichiers. Cela est déjà un peu dommage de ne pas avoir de mécanisme disponible nativement. De plus, ce mécanisme est difficile à coupler avec d’autres permettant d’avoir du fail-over par exemple.
C’est ici qu’HAProxy pourrait intervenir pour résoudre notre problématique car il nous permet d’avoir du fail over et des tests plus fins sur l’état de santé des backends.
De plus, nous sommes en train de tester une solution de second-tier de CDN qui, du fait de la complexité ajoutée à notre architecture de CDN, profiterait beaucoup d’une plus grande finesse de configuration.
“Mais attends, tu n’as parlé que de HAProxy en backend là, tu triches un peu non? C’est pas un sandwich c’est une tartine de HAProxy là!” Tout à fait, notre cas d’usage actuel n’a pas forcément besoin d’un HAProxy en frontal de Nginx.
MAIS!
C’est là que les conférences sont intéressantes car elles montrent que l’on peut mixer les backends.
Dans la conférence présentée par Ricardo, l’utilisation de deux backends (Varnish et hyper-cache) sur un même serveur est permise par un HAProxy. Cela permet de profiter de la complémentarité de ces services.
Dans notre cas, nous n’avons pas besoin de cela mais une autre conférence nous a mis la puce à l’oreille : Writing HAProxy Filters in Rust, by Aleksandr Orlenko.
Cela pourrait nous permettre, avec un HAProxy en frontal, d’agréger plus finement les mesures de performances du serveur afin d’optimiser l’usage de ses ressources, ou déporter une partie du trafic sur un serveur moins chargé, ou encore de récupérer une partie des traitements actuellement effectués par le LBCDN.
Ajouter cette fonctionnalité serait la belle cerise au kirsch au sommet de ce sandwich de HAProxy.

“Il est bizarre ton sandwich”
“Bon d’accord, c’est plutôt un gâteau à étages.”
“Ok c’est mieux, mais je préfère les macarons de la HAProxy Conf 2022 quand même.”
A une prochaine fois !
La HAProxyConf, c’était deux jours de conférences avec des orateurs venus de tous les coins du globe.
Une belle occasion pour nous d’en apprendre plus sur un outil que nous utilisons quotidiennement chez Bedrock.
Dans cet article, nous n’avons pas pu faire mention de tout ce qui nous a intéressé. Nous pourrions notamment citer les très intéressantes conférences au sujet de :
- Docker et leur utilisation de l’outil Keda
- Ou encore de SoundCloud et leurs mesures anti-DDOS
Cette conférence était aussi l’occasion d’échanger avec l’équipe HAProxy autour de sujets techniques qui nous concernent, de voir que nous utilisions déjà certaines bonnes pratiques, mais aussi que nous avions de quoi nous améliorer.
Suite à cette conférence, c’est HAProxy Fusion que nous attendons le plus. Fusion s’annonce comme l’outil idéal pour manager une flotte d’HAProxy. Jusqu’à présent, nous devions utiliser une solution maison HSDO, fonctionnelle, mais très probablement moins bien intégrée qu’un outil directement fourni par HAProxy.