
AWS ALB & NLB currently supports Round-Robin (RR) and Least Outstanding Requests (LOR) balancing algorithms. But what happens when you try to load balance cache servers with these algorithms? How to implement an effective cache in Cloud at scale?
Context
At Bedrock we use both ALB & NLB for different use-cases (like in front of our Kubernetes clusters) in our platforms. For our last VOD platform, we needed to be able to load balance heavy content (videos) to our cache servers. We knew that the balancing algorithm was a key factor for our cache in Cloud at scale, and that ALB & NLB won’t be sufficient to achieve our goals.
Balancing algorithms
Round-Robin is a widely used balancing algorithms.
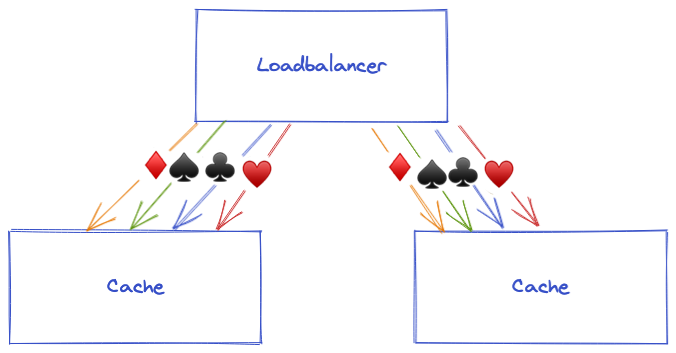
The load balancer cycles through cache servers sequentially, so each cache server should receive an equal share of requests. Each cache server has to possibly store every requested object (♠️, ♥️, ♦️, and ♣️ represent different objects).
With Least Outstanding Requests, load balancers send requests to the cache server with least awaiting requests. The cache server still has to store every requested object.
Consistent Hashing is a very interesting balancing algorithm for caching purposes.
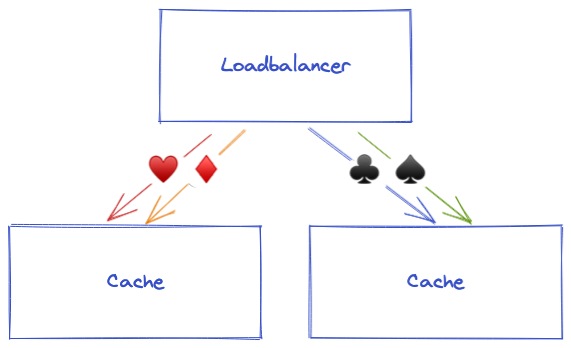
This algorithm allows to distribute the load so that all requests for the same object will always go to the same cache server. This way, each cache server has to store half of the objects.
And more cache servers means more load balancing between the servers.
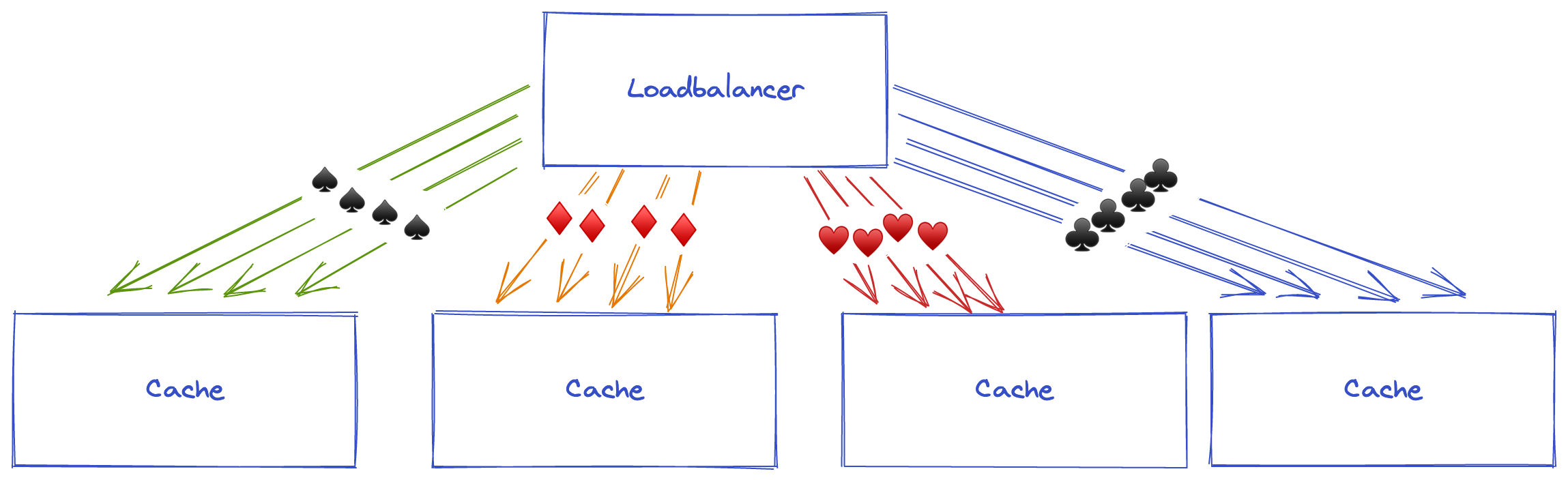
While at scale, Round-Robin or Least Outstanding Requests will look like this:
Cache servers are not efficient at scale with these algorithms. There is a higher chance for the cache to miss, because all servers do not store all objects. Every time a cache expires or cache server boots, objects need to be cached again to be hit. You also need more resources, as the same object needs to be cached on all cache server disks.
With Consistent Hashing, once an object has been cached you have a greater chance for the cache to hit. And you save money by using smaller disks on cache servers and reducing network bandwidth.
HAProxy implementation
Consistent Hashing at AWS is not available with ALB, ELB and NLB. You need to implement it yourself.
To do this, we chose to use HAProxy.
HAproxy is fast and reliable. We use it often, we know it well, and it can use consistent hashing.
This is how we architected it.
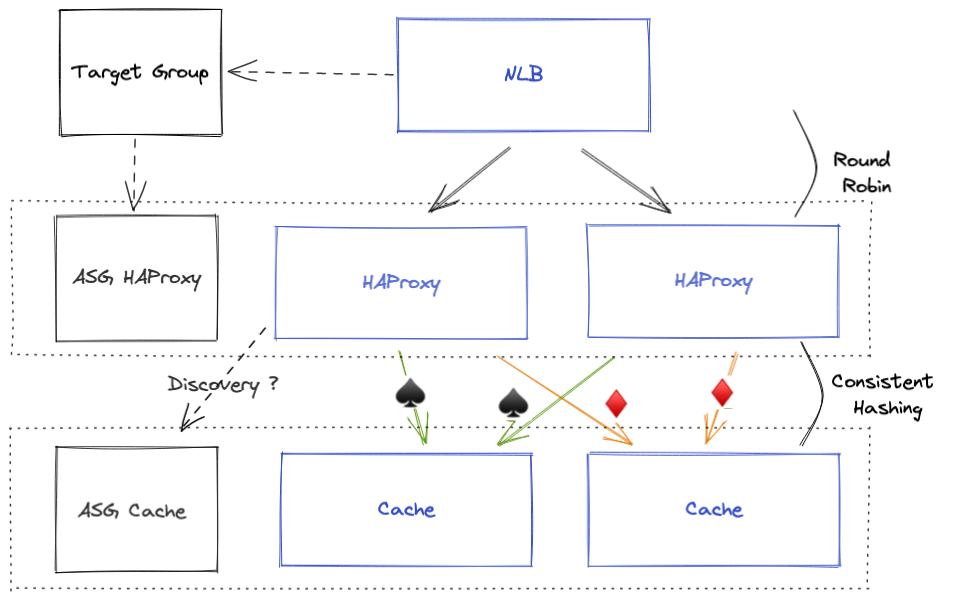
HAProxy servers and Cache servers are deployed with Auto Scaling Groups (ASG). A Target Group is registering HAProxy ASG instances so NLB will load balance between them. Having separated ASG for HAProxy and Cache allows it to have dedicated automatic scaling and management.
We need to implement something for HAProxy so it could discover and register Cache ASG instances. And there is one thing important to do consistent hashing with HAProxy: a centralized and consistent configuration.
Centralized configuration
All HAProxy instances need to have the same configuration with the same list of servers, or requests will be split differently depending on HAproxy instances.
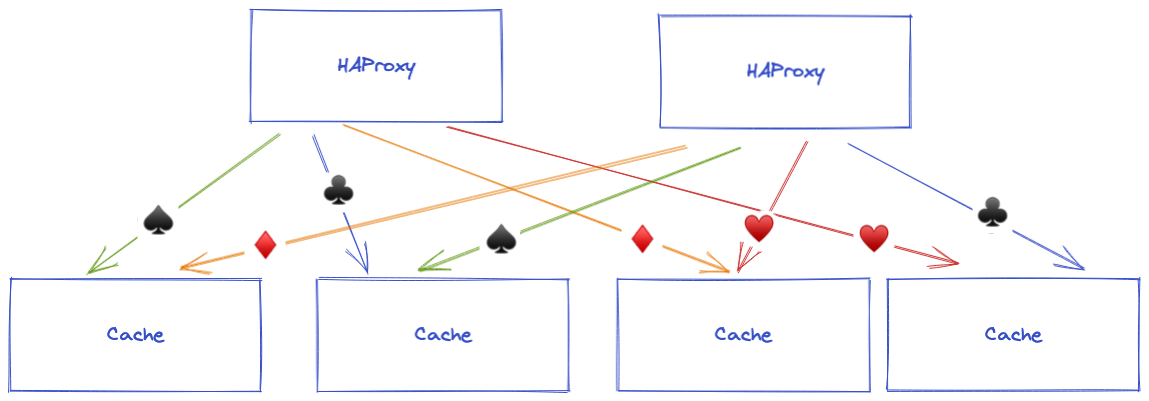
You have a higher chance to have a miss on your cache request as a single object may be at different locations depending on the HAproxy instance. With a centralized configuration, you can be sure that each HAProxy instance will request the same cache server for the same object.
Consistent configuration
HAProxy consistent hashing is based on backend server IDs. These IDs match the position of the server in the backend server list. For example, this HAProxy configuration:
backend cache
server CacheA 192.168.0.1:80 #ID = 1
server CacheB 192.168.0.2:80 #ID = 2
server CacheC 192.168.0.3:80 #ID = 3
server CacheD 192.168.0.4:80 #ID = 4
will be seen as the following:
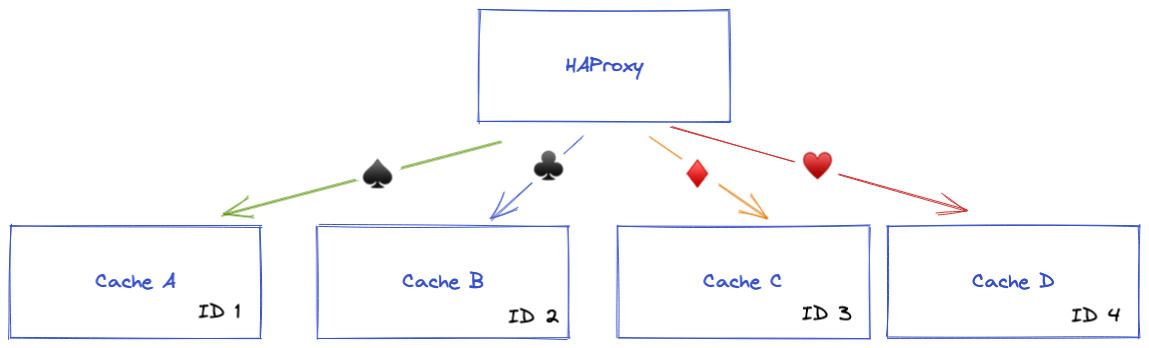
To keep consistent hashing efficient, cache servers need to change ID rarely. HAProxy backend server list must be consistent across all HAProxy instances.
If CacheC is removed, configuration has to be like:
backend cache
server CacheA 192.168.0.1:80 #ID = 1
server CacheB 192.168.0.2:80 #ID = 2
server CacheC 192.168.0.3:80 disabled #ID = 3
server CacheD 192.168.0.4:80 #ID = 4
CacheC backend server is now disabled until another Cache server takes its place.
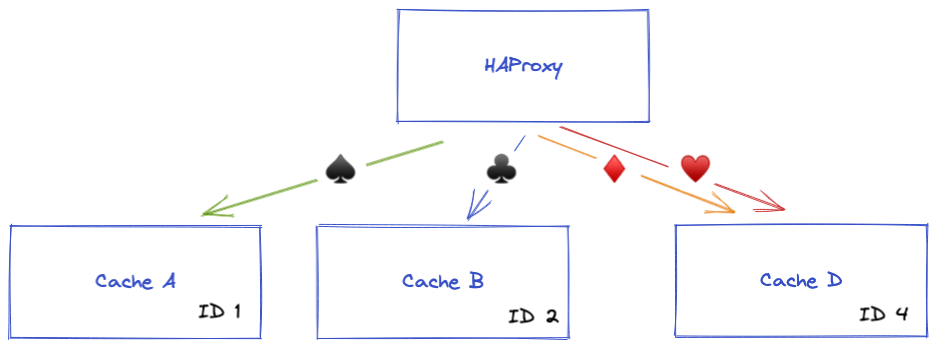
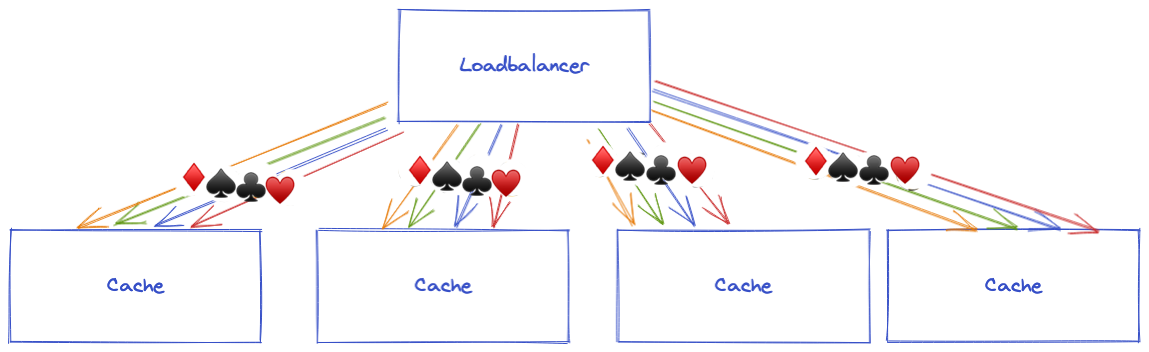
With consistent configuration: ♠️, ♣️ and ♥️ requests are always balanced to the same cache servers, while ♦️ requests are balanced to another available cache server.
Without consistent configuration: all requests could be rebalanced to other cache servers. This would mean that for each cache server scale up or down, we no longer have the cached objects: we MISS the cache. This would be inefficient: we would lose the advantage of the cache.
Solutions
Consul
At first, we started to configure HAproxy through Consul. We already used it at BedRock, and an article gave us hope to quickly achieve what we wanted. Consul Service Discovery with DNS won’t provide sorted/consistent DNS records by design. We can’t have a consistent configuration with it.
Another way of doing so would be to use consul-template for generating backends and registering servers into an HAProxy configuration file. With this approach, we would reload systemd to add new servers to HAProxy.
But HAProxy Runtime API is the recommended way to make frequent changes on configuration, service reloads are not considered safe.
AWS EC2 Service Discovery
HAProxy also released a new functionality called AWS EC2 Service Discovery in July 2021. We haven’t tested it yet, but it lacks the possibility to keep a consistent list of servers between HAProxy instances, which isn’t good for consistent hashing as discussed before. We opened an issue on HAProxy dedicated Github repository.
Added to the fact that we were starting to think that Consul was overkill for our needs, we start to implement our own solution.
HAProxy Service Discovery Orchestrator
What we wanted to achieve was to use maximum managed service from AWS, meet our standard of stability and resilience, and keep things simple. We choose Python with boto3 to implement our solution as it is one of our team’s favorite languages.
HAProxy Service Discovery Orchestrator (or HSDO) is open-source.
HSDO is composed of a server and a client.
HSDO Server
HSDO Server runs in standalone. It could be a Lambda, but we were more comfortable with system processes when we designed it.
Its job is to keep track EC2 instances of one or multiple Cache ASGs and update a list accordingly.
HSDO server provides a consistent sorted list of instances. Every time a new cache server appears in the ASG, it is added to the list at a given ID that will never change.
This list is stored in DynamoDB.
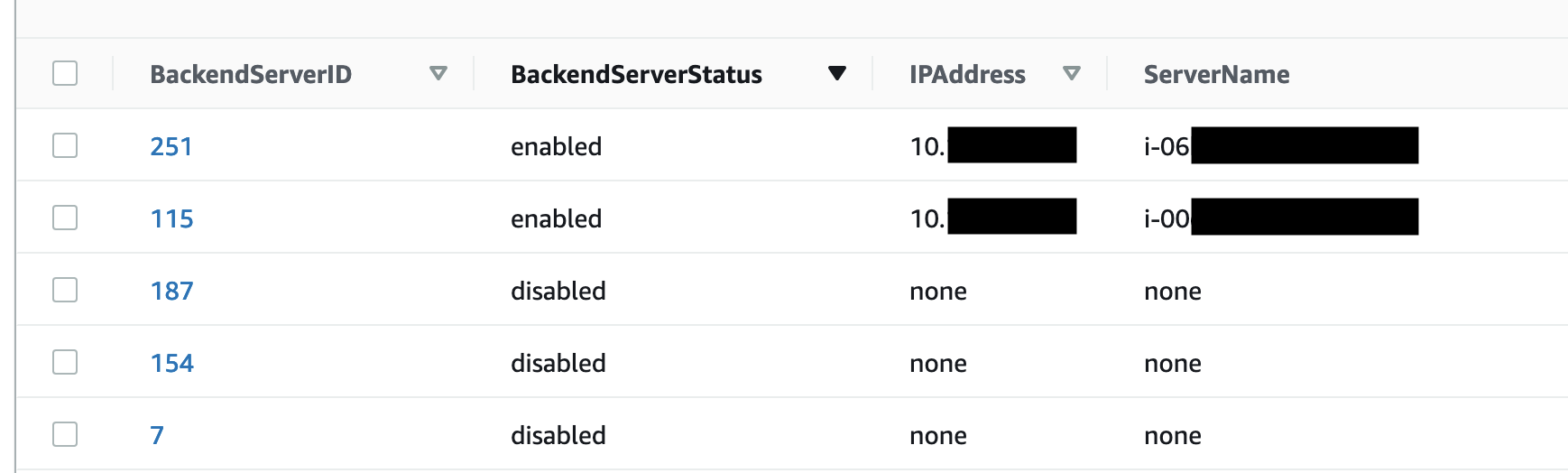
HSDO Client
HSDO client is reading the DynamoDB table to get the cache servers. The client run on the same instance as HAProxy and use the runtime API to update HAProxy config.
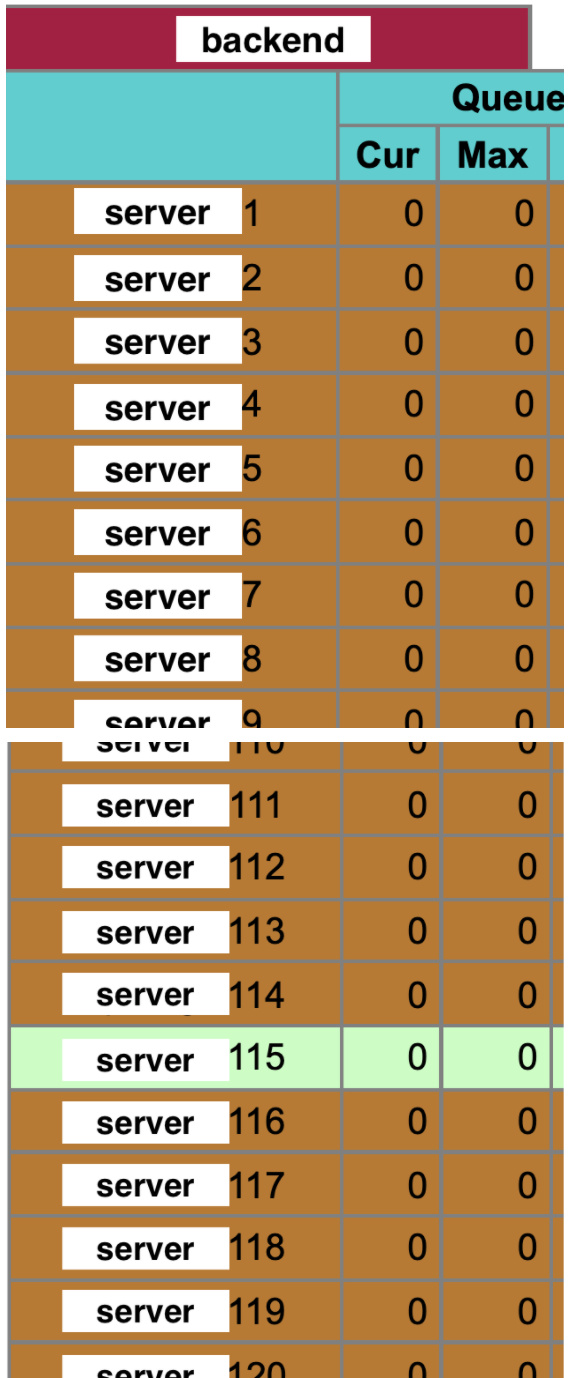
Brown lines are disabled servers, while green lines are servers stored in DynamoDB as seen above.
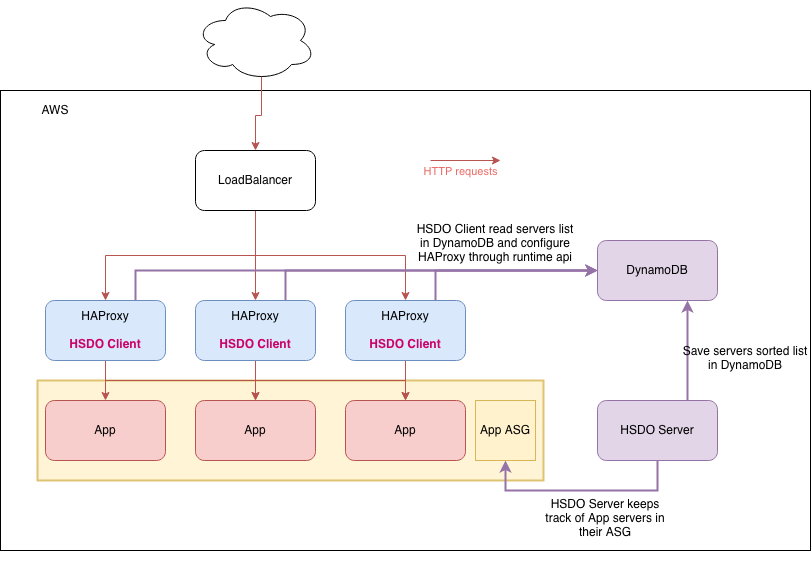
With this architecture, we achieve a centralized and consistent configuration to make consistent hashing work at scale for cache servers.
Conclusion
We have been using HSDO since September 2020. We are distributing VOD content for Salto and 6play streaming platforms and are able to handle at least 10.000 requests/s. This wasn’t possible without a few improvements (on platform cost, timeout funnels, …) and this will be presented in another post, so keep in touch. ;)
Special thanks to all Ops team members in BedRock Streaming for re-re-re-and-rereading this blog post.