
At Bedrock we use Cloudfront or Fastly for two different reason. To protect our applications from potential Distributed Denial of Service Attack. And to provide a layer of cache in front of our applications. No need to go down to the app for an easily cacheable response.

At least that is what we thought in 2018 when we were migrating from on premise to the Cloud.
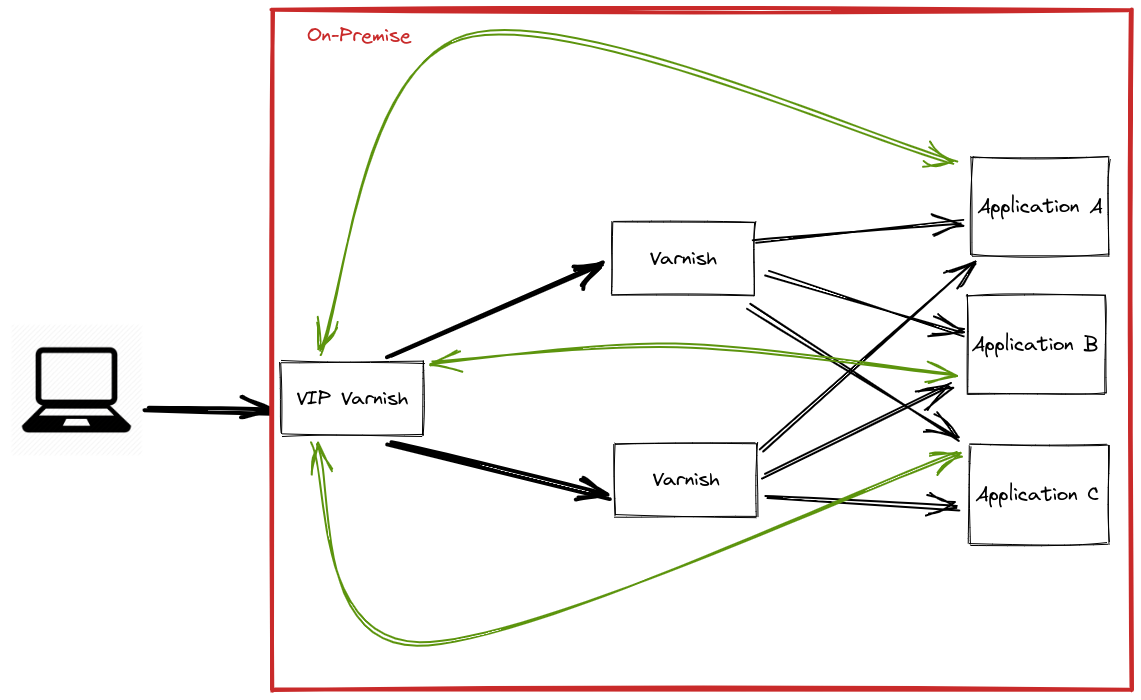
At that time we had a Varnish instance caching everything at the border of our on premise infrastructure. All the applications were running either on virtual machines or on bare metal servers. Those applications were mostly called by the end-user’s browser. Whenever an application called another application it did it through Varnish.
This is ideal if applications are mostly called from the outside world. The Varnish instance caches all cacheable content, and it does not cost too much time as it was in the same Data Center.
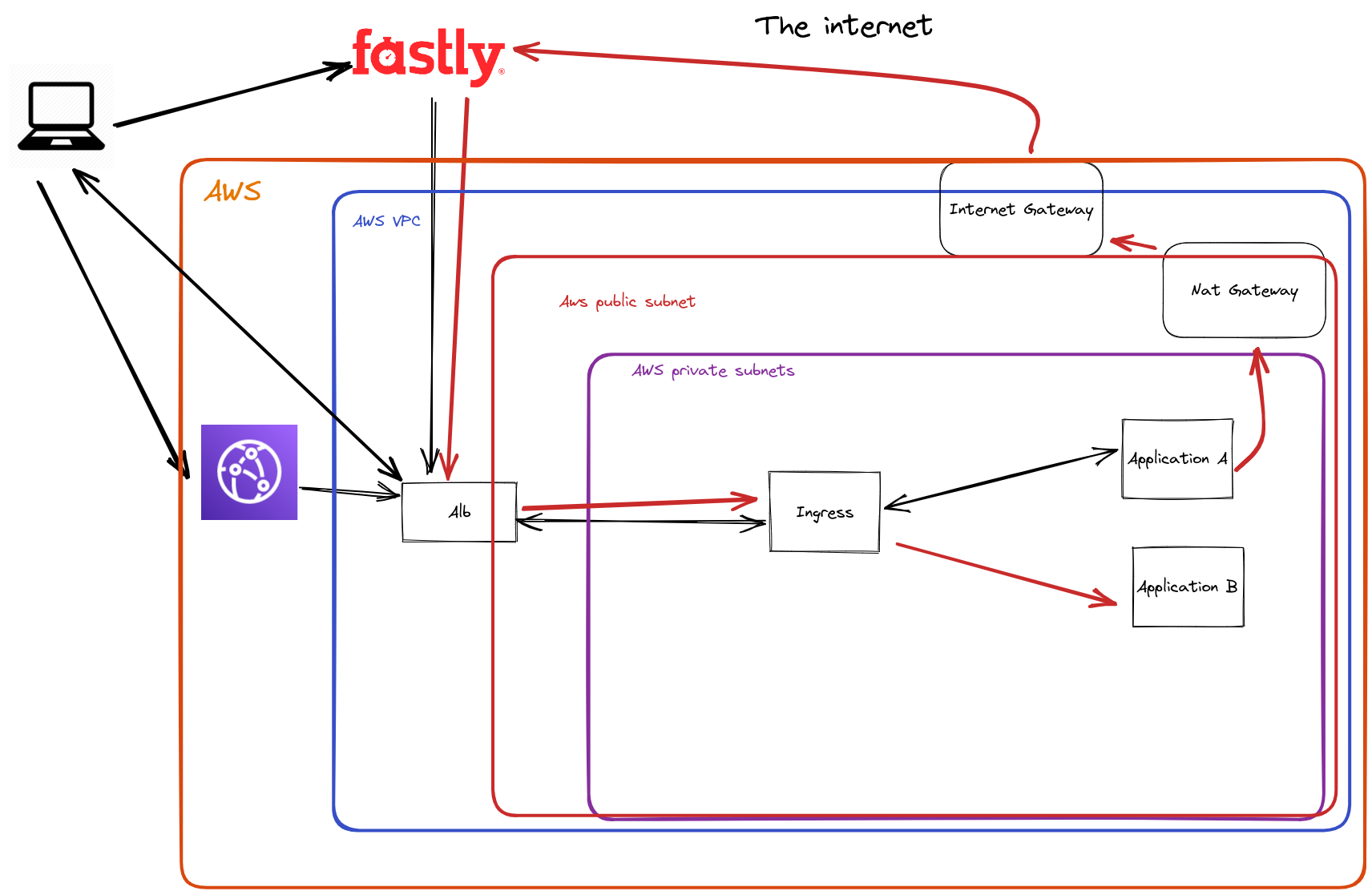
In 2023, we think otherwise. We have now a KOps managed Kubernetes cluster running on EC2 spot instances in private subnets at AWS. As we migrated to the cloud we also embarked on the journey of splitting monolith into smaller more manageable microservices.
With less monoliths the Bedrock product is more resilient and easier to scale but it changes the topologies of network calls. Before there were far more calls coming from the internet from end-users browsers. Now with the new architecture coming into place inter-app requests have increased.
One solution would be to directly call the ingress of the applications, staying inside the cluster but without the benefit of caching as it is handled by the CDN. This would lead to unsustainable increase in CPU usage, and probably very little gain in terms of response time.
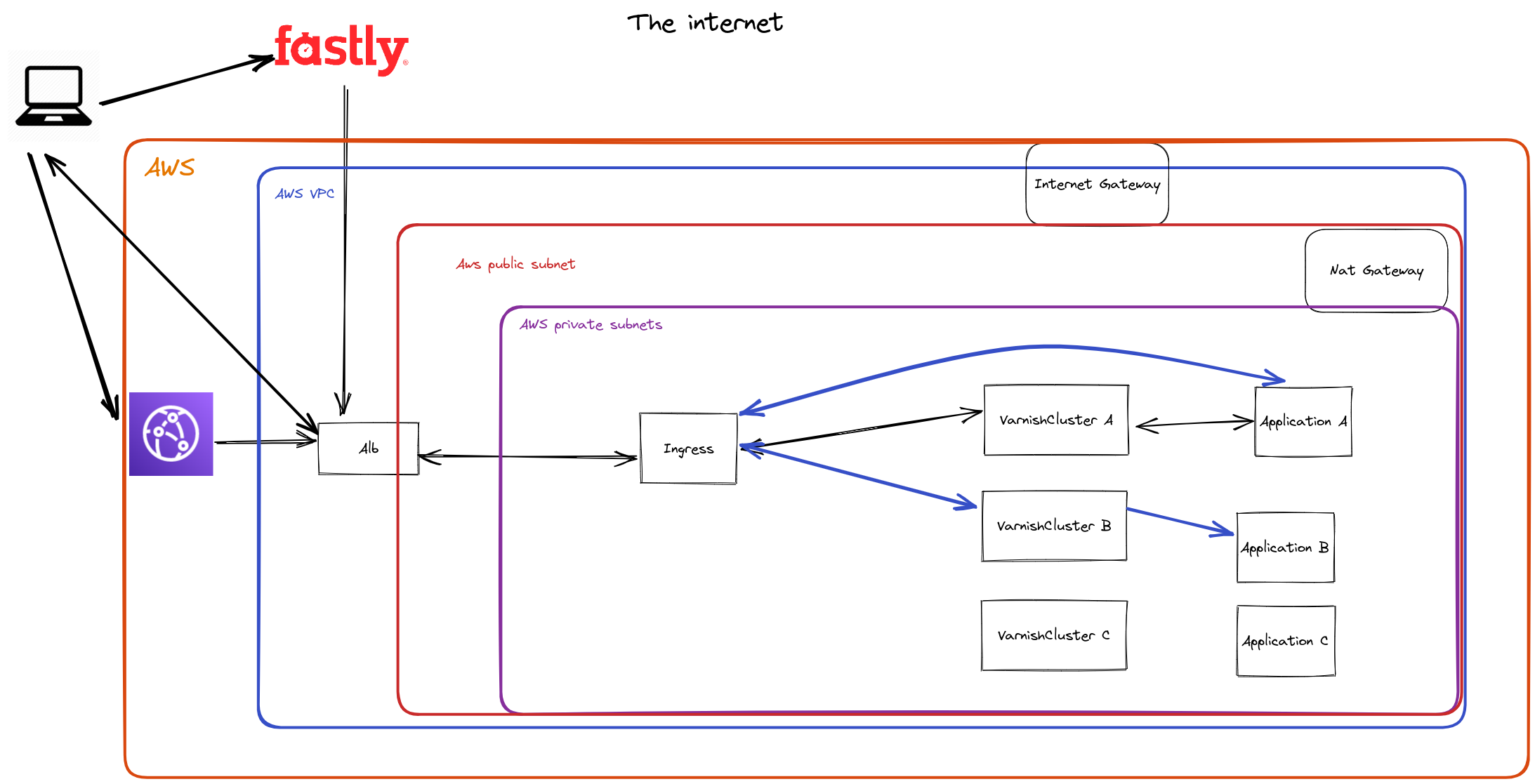
A better solution for us would be to have the caching of CDN inside the cluster. This would enable us to have fast response time and little to no increase in CPU usage.
Enter Varnish-Operator
We tested the project IBM/Varnish-Operator. This project allows us to create Custom Resources for Kubernetes handled by the Varnish-Operator. This object is called a VarnishCluster, the configuration is pretty simple to get started. This enables us to have a caching layer, between the Ingress-Controller and the Application.
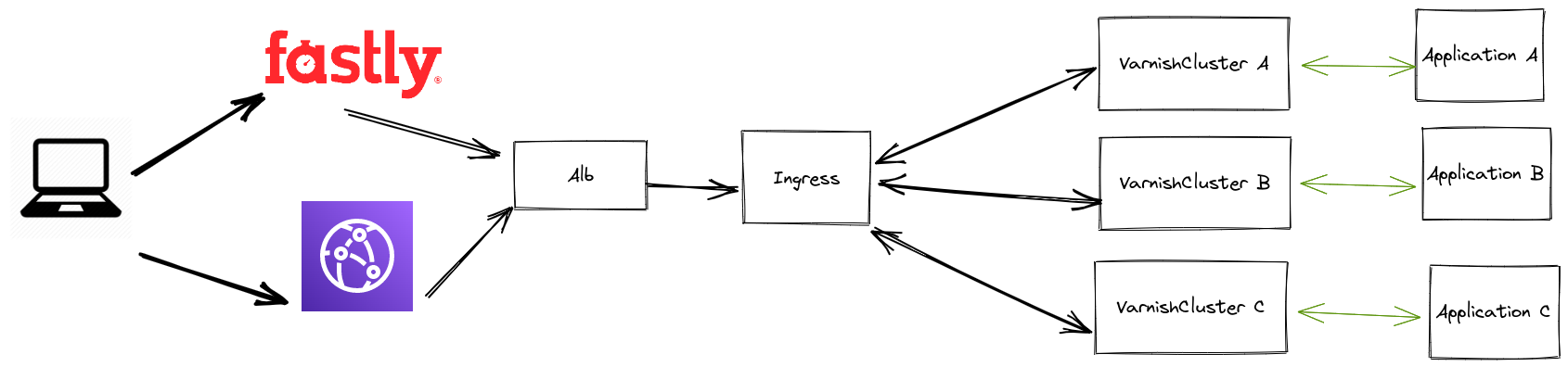
VarnishCluster also uses Varnish Configuration Language (VCL) which we are pretty familiar with since we use Varnish On-Premise since 2015, and developers use it regularly to configure Fastly distribution.
By adding cache using VarnishCluster to an application that is not fully cacheable, we almost divided it’s average response time by two. It is not a surprise as inter api calls used to look like the following graph:
We changed parameters in the application after adding VarnishCluster so that it calls other app inside the cluster like in the following graph:
A few details
Before I wrap this up, here are a few details about the implementations.
As you will be able to read in the Varnish documentation:
“By default Varnish will use 100 megabytes of malloc(3) storage for caching objects, if you want to cache more than that, you should look at the
-sargument.”
So if you give many Gigs of memory to your Varnish container it won’t be attributed to the Varnish process. You can set it with the argument -s storage=malloc,<Number>.
As we use only Spot nodes that can be terminated by AWS at any moment with only 2 minutes notice, we want to give more resilience to our Varnish Clusters pod as cache is stored in RAM memory. You lose all your cache at each restart of the Varnish Container.
We configured podAntiAffinity between application pods and VarnishClusters’ to avoid scheduling those pods on the same node and be vulnerable to reclaims.
We added a podDisruptionBudget to avoid losing all our pods at the same time. We also customized the VCL a bit to make Varnish serve stale content in case our application is unreachable.
We also added a Prometheus Service Monitor to make sure all Varnish metrics would be scraped by Victoria Metrics.
In the Future
In next versions we would like to add the possibility to configure PriorityClass of VarnishClusters pod. PriorityClasses are used to order workloads priority. In a context of scaling and of scarcity of resources, the scheduler will evict pods of lower priority to make room for the pod it is trying to schedule.
For now our VarnishCluster’s pods have the PriorityClass by default but it is more critical than any other applications as it holds a cache in its memory.
Also we do not have logs of Varnish. We would like to be able to stream VarnishLog content into Loki. This would be super useful to debug and to investigate if we ever encounter bugs or unexpected behaviors.
Conclusion
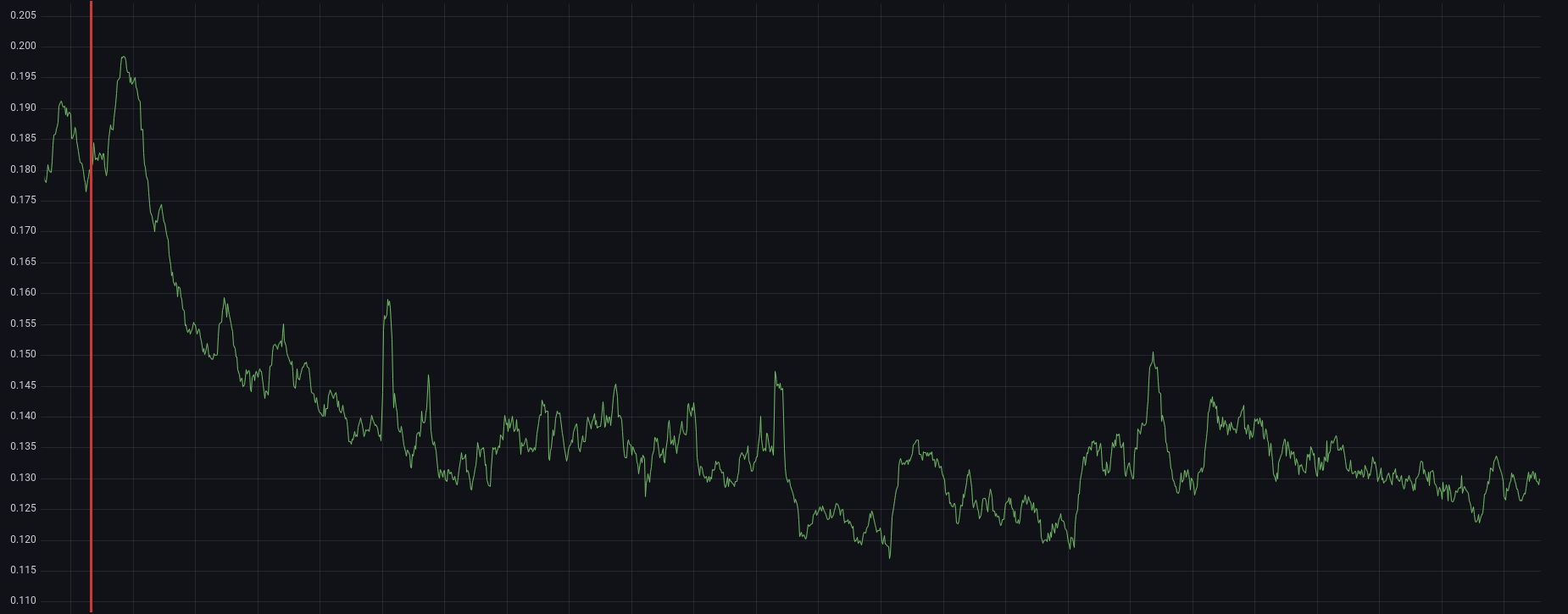
Average response time going down, red bar is when we pushed it in production
With the generalization of microservices, Bedrock needed to rethink its architecture to optimize not only for browser to API calls but also for more API to API usage. By adding VarnishCluster in front of our applications and calling them directly from inside the cluster we improved significantly the Bedrock product.
The Github project is still young and lacks important features, we hope with this article to help draw attention to this project and potential contributors.
