Here’s our journey to migrate tens of thousands of videos, accessed by millions of users, to the cloud. How we minimized our costs without losing the biggest benefit of the cloud: scaling.
The purpose of this article is to show you the evolution of this cloud video delivery platform, from the first draft to the current version.
Table of Contents
- How we do streaming
- Just In Time Packaging
- Version 1: The quest for self
- Version 2: Let the requests flow
- Version 3: Cost Explorer Driven Development
- Optimizations
- Conclusion
How we do streaming
To stream video, we cut each video file in 6 seconds chunks. The video player loads the associated manifest, which lists these pieces and in which order it must read them. It then downloads the first video chunk, plays it, then loads the second chunk, etc.
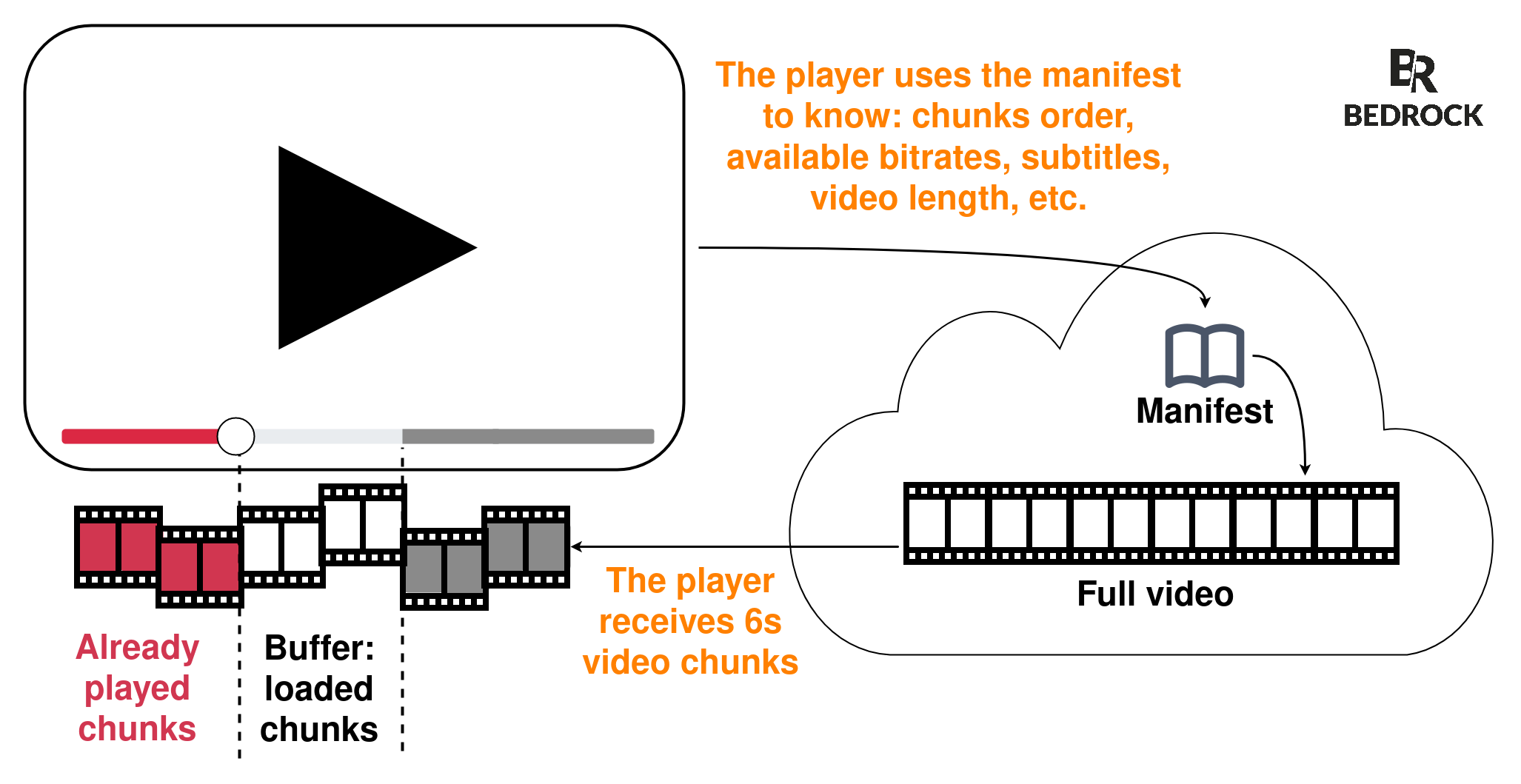
A video is composed of several chunks.
For example, a 90 minutes movie, with a duration of 6 seconds per chunk, means 90×60÷6=900 video chunks called from the player plus another 900 audio chunks. A total of 1800 different chunks for a single video.
Just In Time Packaging
A client calls a manifest and chunks to play a video.
Depending on the format (Dash, HLS, Smooth) a client supports, it will request one of three kinds of manifests+chunks.
The Unified Streaming software handles these calls. Unified Origin (which we call USP) fetches the associated video from a AWS S3 bucket. It relies on a server manifest (.ism file), stored with the video, to respond with the video format the client requested: Dash, HLS, etc.
So, we store a complete video and its server manifest on S3, and USP provides the client with a client manifest and specific chunks: this is Just In Time Packaging (JITP).
Another way is to compute all the chunks and manifests in advance and write them to S3: this is offline packaging.
In this case, once packaging is done, there is no need to do these calculations anymore: it lightens the architecture and avoids the availability challenges of doing real-time computing.
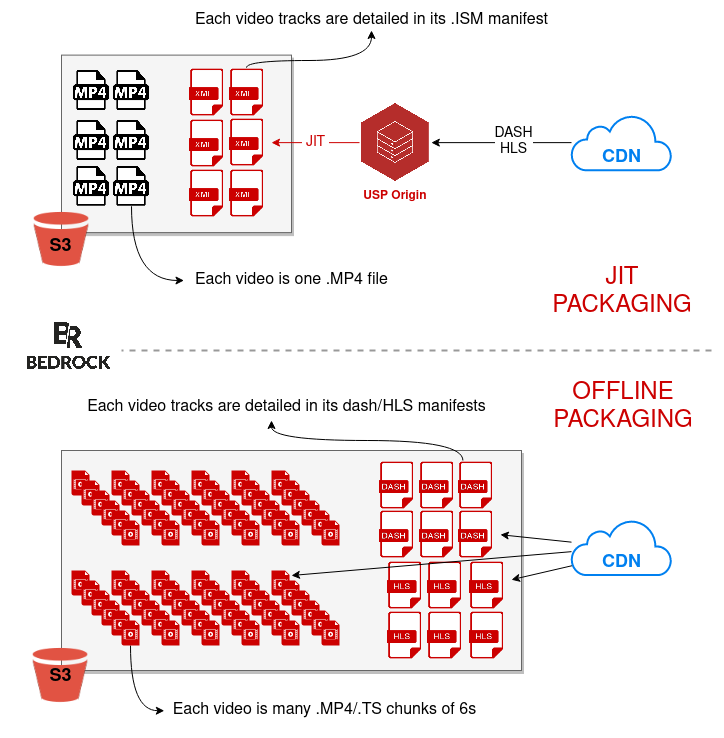
Still, this causes a big cost problem. On AWS S3, you pay for data access (GET requests), as well as storage. The more you store, the more you pay and the more you access, the more you pay.
i.e, a 90mn video, played in Dash, is cut into 900 chunks plus a single Dash manifest. The same video in HLS, it’s 900 different chunks and another manifest: 1802 files written on S3. Add the Smooth Streaming format and you get 2703 files stored on S3, for a single video.
Offline packaging is interesting, but incompatible with our need to manage a large number of equipments and vast catalogs: tens of thousands of program hours per customer.
Another approach, which uses the best of the two above solutions, is possible: the CMAF (Common Media Application Format) standard.
The player is able to chunk the video itself by adding the HTTP header Range: Bytes.
Many devices, especially connected TVs or old Android versions, are not compatible with CMAF, which is why the rest of this article will focus on Dash/HLS in JITP.
Version 1: The quest for self
We were using USP on-prem. We decided to migrate it to the AWS cloud.
The goal of the V1 was to quickly provide a platform to our video teams to work on and certify the video players. For Bedrock Ops team, it was a first stepping stone building this platform.
Let’s detail the components of this V1.
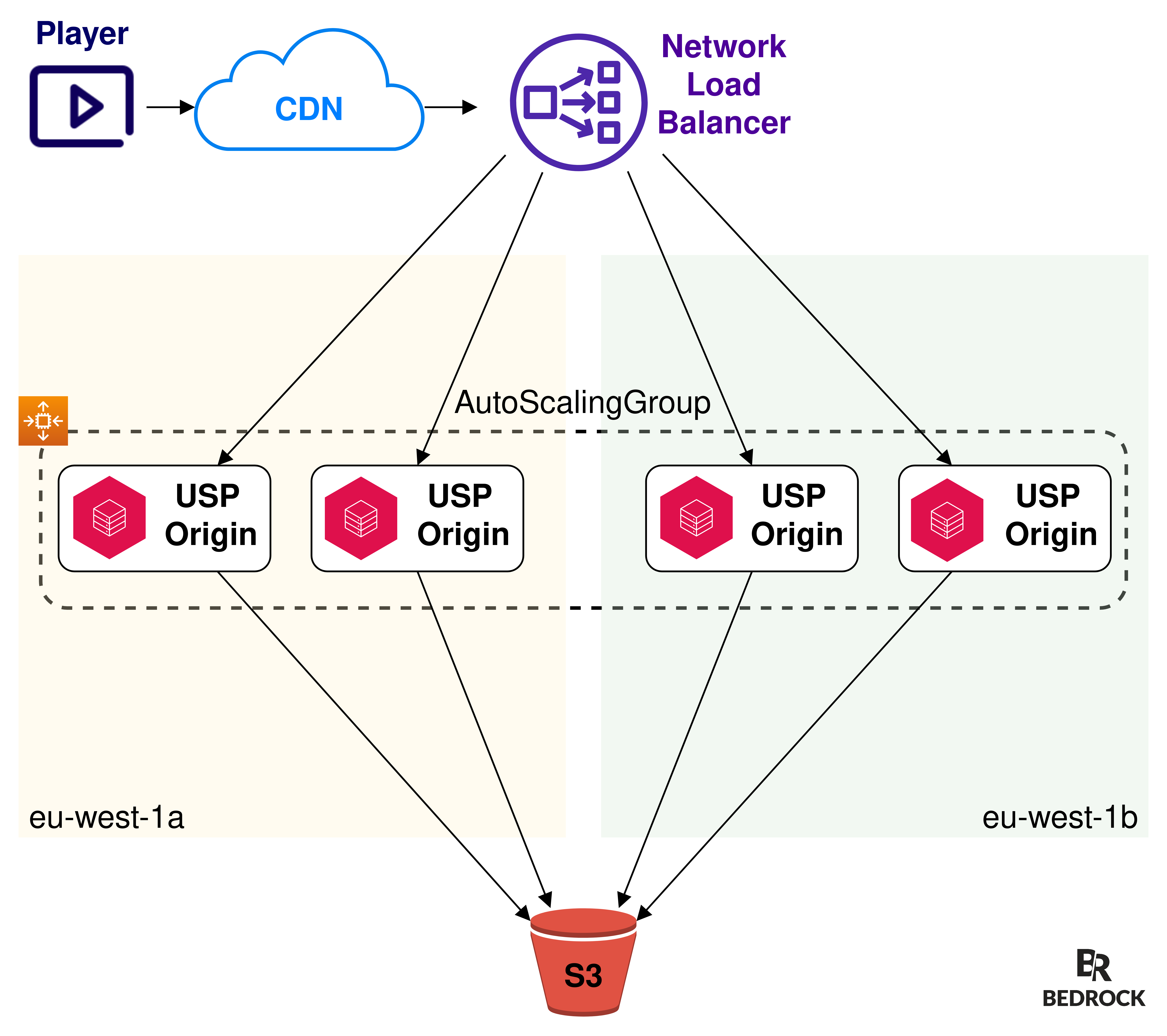
- Players send their requests to a CDN.
- The CDN uses a network load balancer as its origin.
- The network load balancer forwards requests using a Round Robin algorithm, to multiple AWS EC2 instances we call “USP Origin”. These EC2 instances are controlled by an AutoScalingGroup and are dynamically scaled based on their network or CPU usage.
- EC2s retrieve files from the S3 bucket.
Local cache with Nginx
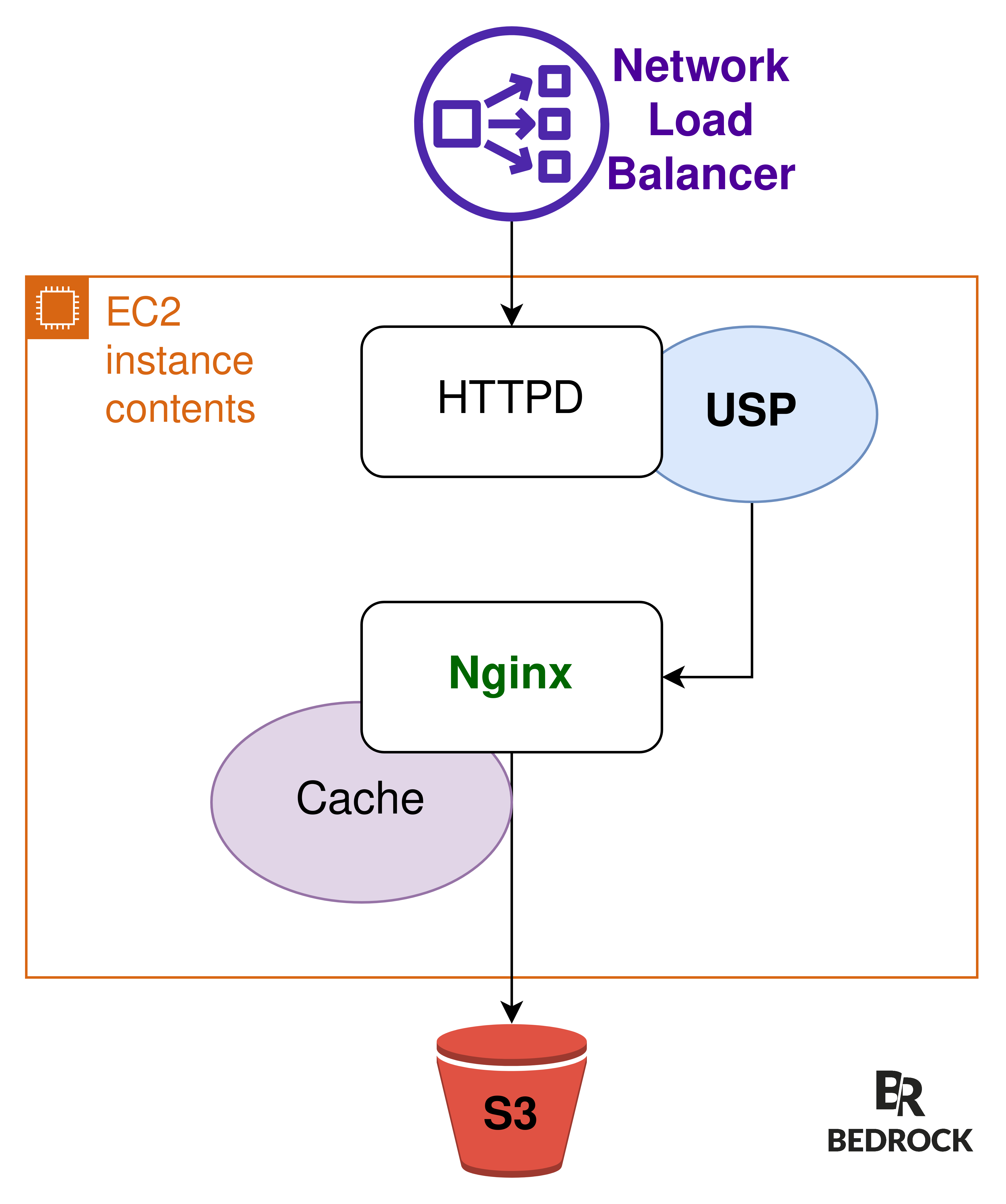
On EC2 instances, USP runs as a module of Apache HTTPD.
When a player requests a specific video chunk, it sends an HTTP request to HTTPD. The USP module it embeds will:
- load the according .ism file from S3 (the server manifest)
- load the video metadata, stored in the first 65KB and the last 15B of a .mp4 file on S3
- load the specific chunk from the mp4 container, according to the player’s information: bitrate, language, etc. (still on S3)
For each video chunk called from a player, the USP module does another call to the S3 bucket, loading the same .ism manifest and the same metadata (first 65K and latest 15B).
To avoid these calls and reduce S3 costs by 60%, we added Nginx on these EC2s. It goes between HTTPD and S3, to cache the manifest .ism files and metadata of .mp4 video files.
We’re using LUA in the Nginx vhost, to cache these 65KB and 15B requests made by USP to the S3 bucket.
We use Nginx for caching because we have a solid experience with it, under heavy load, on our on-prem edge servers, which each delivers up to 200Gbps of video traffic. We want to capitalize on this expertise and avoid spreading ourselves thin on multiple tools (e.g, Apache Cache module).
I recommend reading the article published by unified streaming, which uses a similar method: caching via httpd directly.
Network Load Balancer: manages TLS and helps with scaling
We’re using Network Load Balancers to offload TLS. They are cheaper than Application Load Balancers and we don’t need to interact with the HTTP layer: this is not the role of the load balancer, we prefer to keep a KISS principle.
The major advantage of NLBs is a single entry point (a CNAME domain name), which distributes the load over n EC2 instances. This is essential for auto-scaling: nothing to configure at the CDN level, the load balancer will distribute the load among all Ready instances, whether there are 2 or 1000.
AWS managed load balancers are also interesting because certificates are auto-renewed. Another advantage is that they are distributed over all the availability zones, which was one of our prerequisites in our multi-AZ strategy.
Content Delivery Network: Keep It Simple and Stupid
We’re using Cloudfront CDN with a basic configuration: we respect standards and use Cache-Control header.
We’re also using our on-prem Edge servers and other CDNs. Likewise, they all respect the HTTP protocol RFCs and we provide a valid Cache-Control header to be CDN agnostic.
A first conclusion: V2 needs Consistent Hashing
V1 of this platform allowed our video teams to work on new features and new software versions quicker, compared to on-prem. It was also new for Infra teams: we wanted to understand how to scale the platform on AWS to meet our load requirements, making the best use of managed services and auto-scaling, which we did not have on-prem.
We have identified the problem of version 1 during our tests: the cache is ineffective under heavy loads. The Round Robin algorithm (used by the NLB) is not adequate in front of cache servers because each server will try to cache all the data and will not be specialized to a part of the data. The more requests we have, the more servers we will add and the less each server will have a relevant cache.
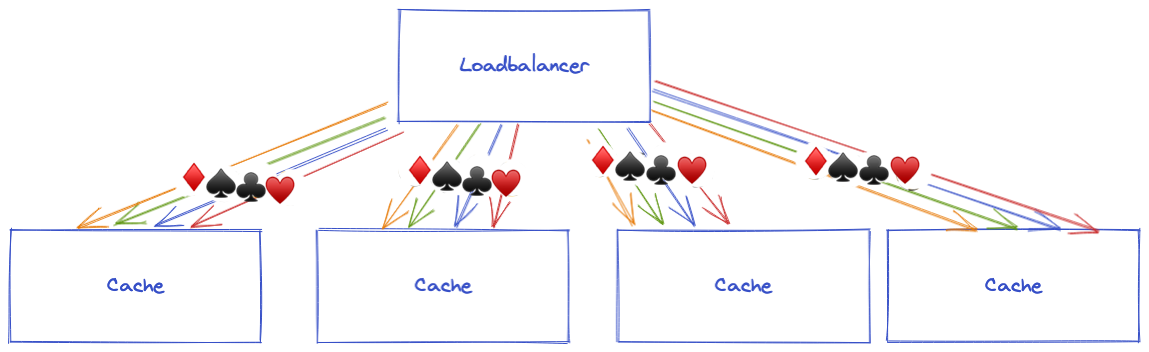
To use the cache as much as possible, we need an adapted load balancing method: Consistent Hashing.
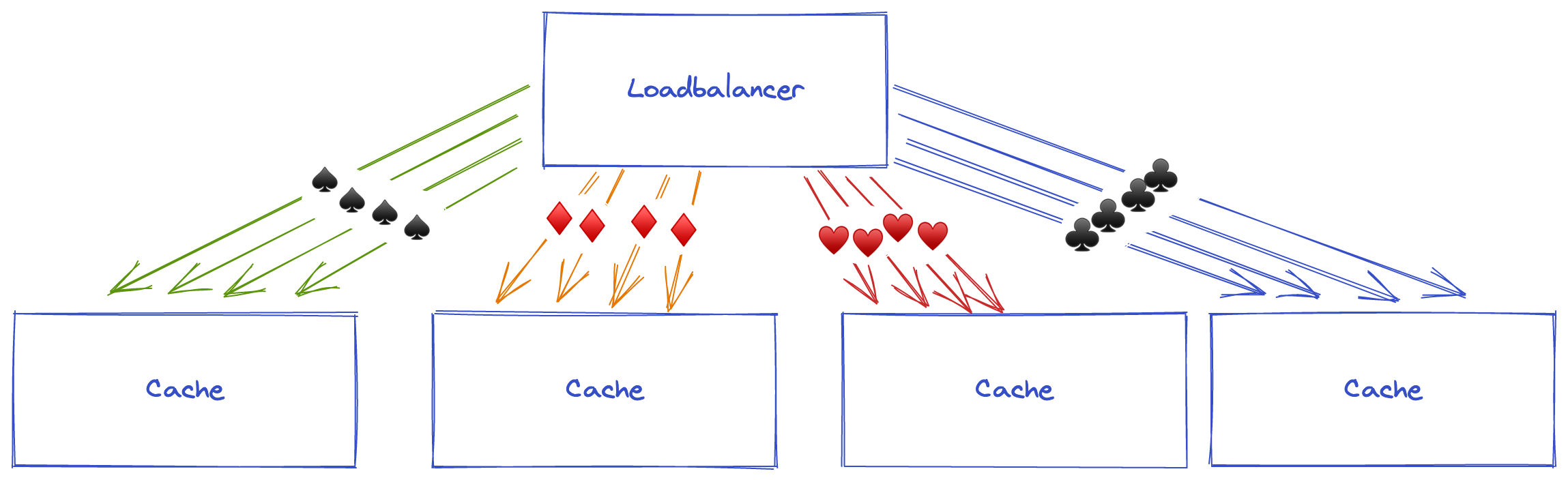
Last two images are from our recent blog post about doing advanced load balancing at AWS.
With Consistent Hashing, we can send all requests for the same video to the same cache server. This would optimize the local Nginx cache and reduce S3 costs.
Version 2: Let the requests flow
V2 will be used in production, with thousands of requests per second: we need it to handle the load, to be reliable and robust.
According to our strong experience with HAProxy, we know that it is able to do Consistent Hashing with Bounded Loads, which is exactly what we need.
We started by adding HAProxy servers between the load balancer and the USP servers.
HAProxy to make Consistent Hashing
HAProxy is running on EC2 instances, in a dedicated AutoScalingGroup. As with the USP AutoScalingGroup, this one scales with AWS scaling policies: network bandwidth or CPU consumption. We can launch hundreds of HAProxy servers if we need to, and their scaling is independent from the number of USP servers (but they are often linked).
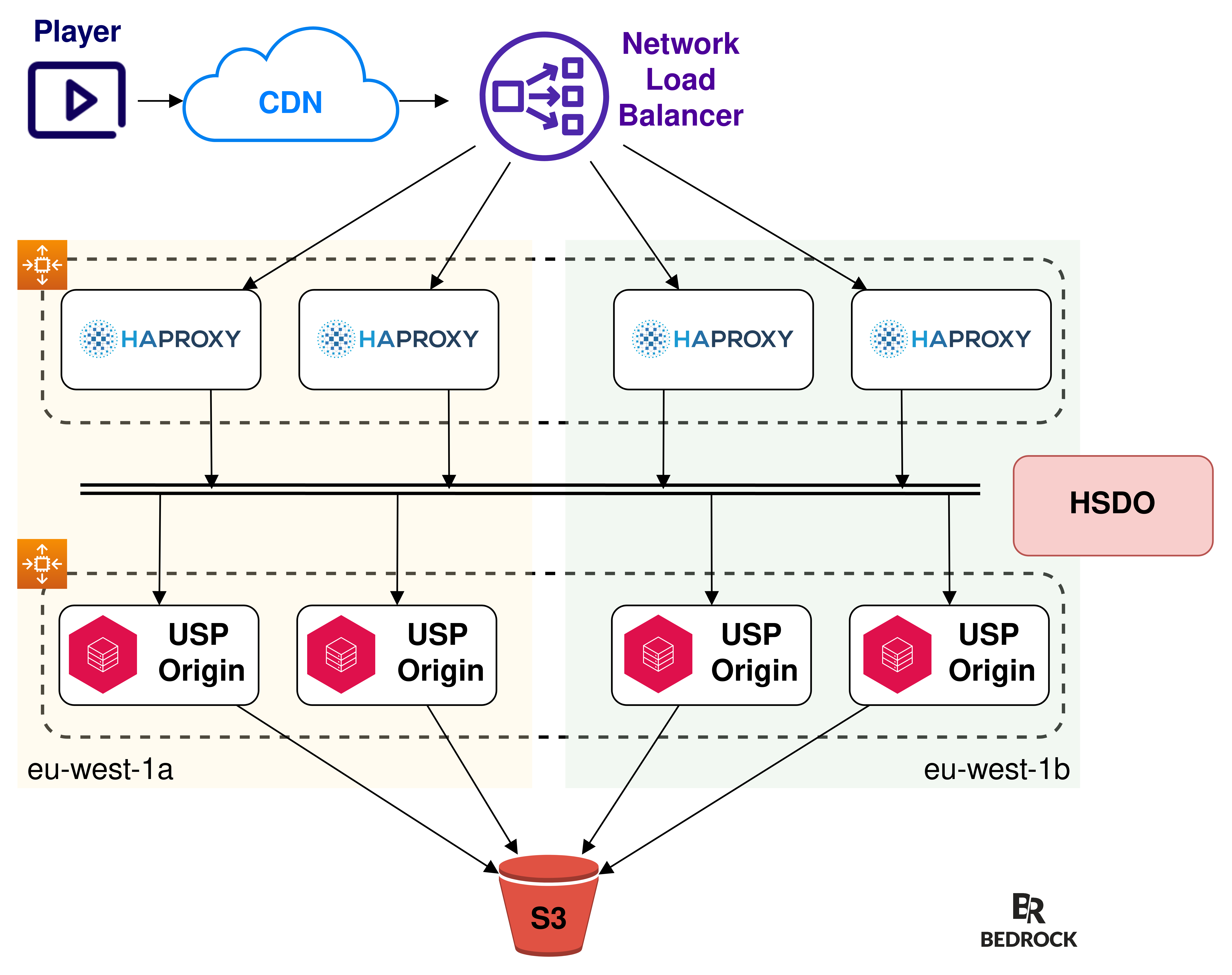
To send requests to USP origin, HAProxy needs to know all the healthy EC2 instances running in their AutoScalingGroup.
We started by using Consul, to automatically populate our HAProxy backend with these USP servers.
See the dedicated blog post to know why we preferred to develop a tool dedicated to this task, which we called HAProxy Service Discovery Orchestrator (HSDO).
EC2 costs are reduced by using only Spot instances
In addition, HSDO is very responsive to movements in the AutoScalingGroup, which allowed us to replace all EC2 On Demand instances with Spot instances.
And by all instances, I mean all USP servers (with cache), as well as HAProxy servers: 70% reduction in server costs.
Note that replacing USP origins with Spot instances has almost no impact on the cache, as we follow the AWS best practices for Spot: use many different instance types, be multi-AZ and use the “Capacity Optimized” strategy. This way we observe very few reclaims, which translates to a longer cache life.
Production launch on this V2
The production launch of this V2 has confirmed the stability and performance of the platform. We were happy to see that our objectives were met, so we started migrating all our VOD content from on-prem to the cloud, video by video, client by client.
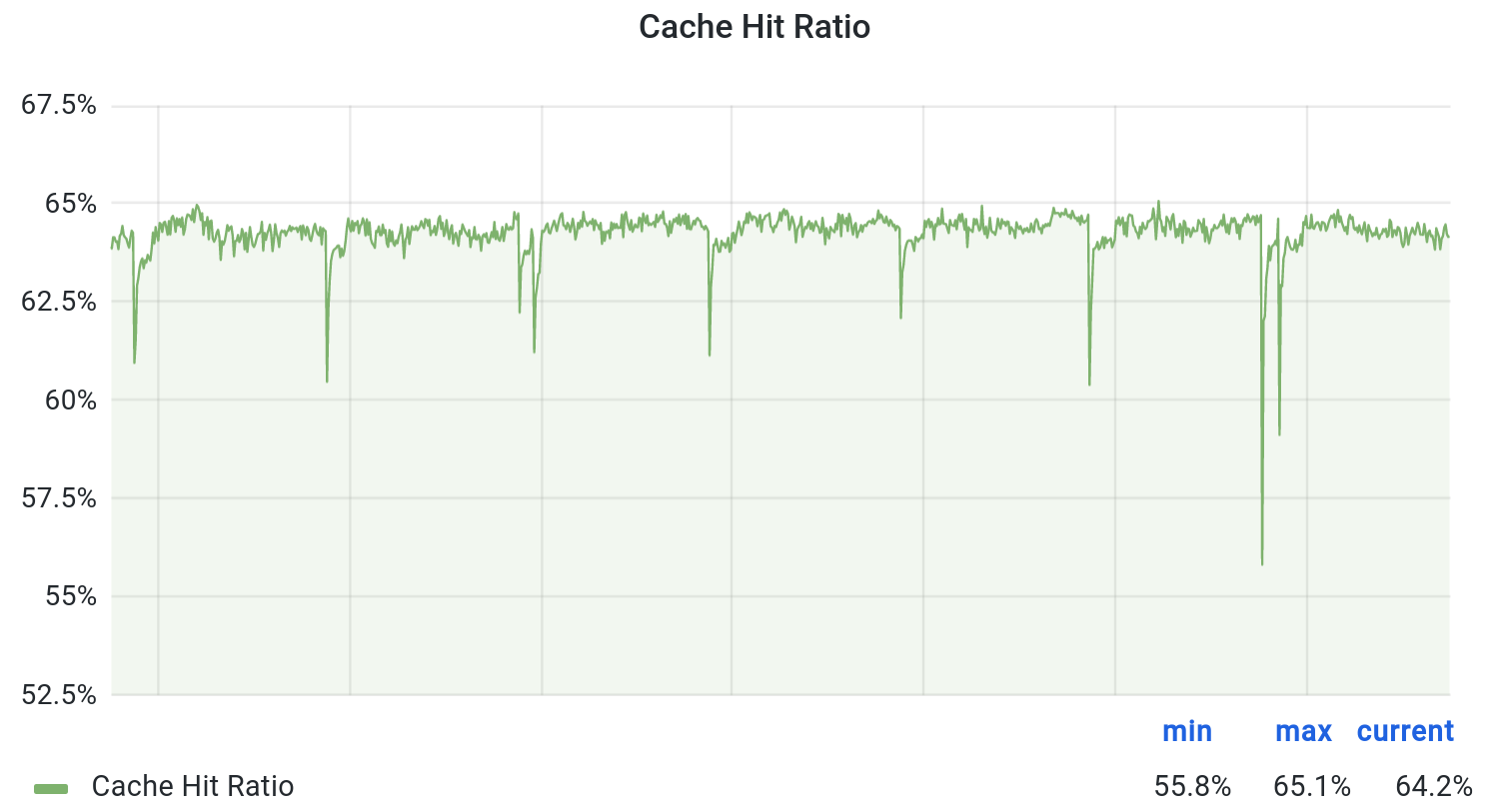
With Consistent Hashing, the cache becomes quite efficient and we saved 62% of calls to S3.
In addition, the cache speeds up the video packaging and we have reduced the overall origin response time. Win-win.
EC2-other: the financial abyss
EC2-other, in this case, means network traffic between Availability Zones.
The private network between two data centers (AZs) at AWS is re-billed and accounted for 48% of the bill for our VOD platforms at the time.
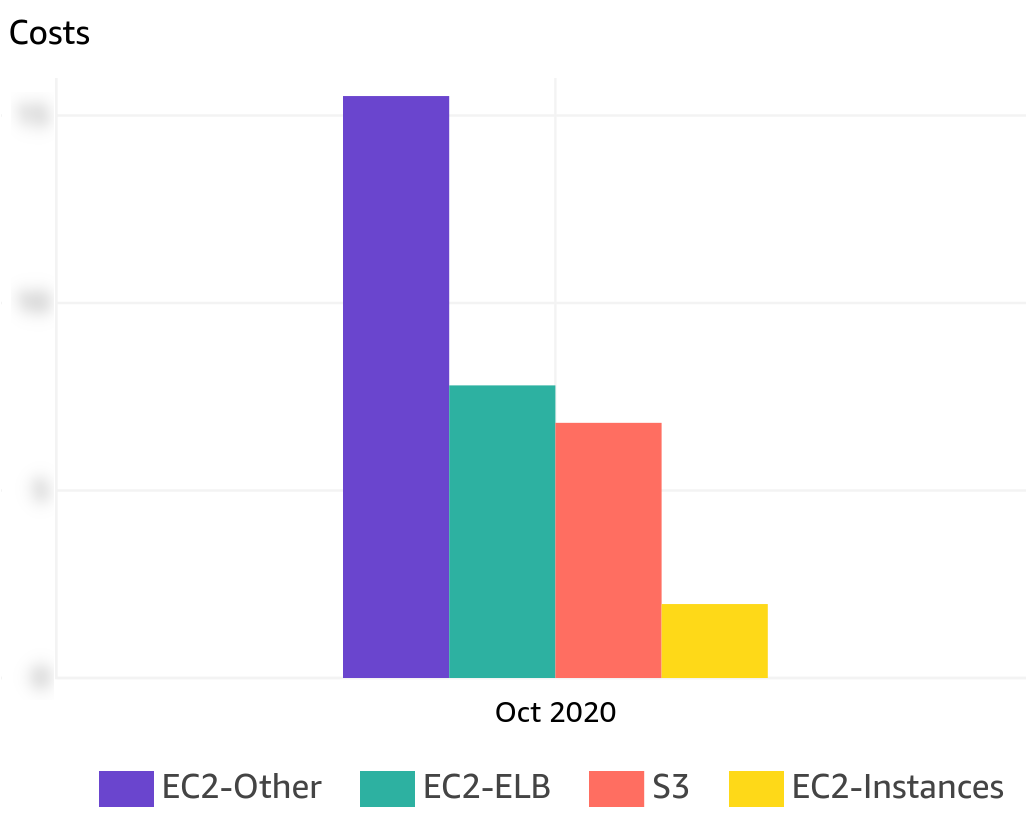
When HAProxy servers sent/received traffic from USP servers, the latter might not be in the same Availability Zone and the traffic between the two was charged at full price.
It was necessary to quickly find a solution for these costs which torpedoed the project. We started the creation of version 3 as soon as we had these metrics from version 2, at the beginning of our VOD content migration.
Version 3: Cost Explorer Driven Development
The idea is to do as well for half the price.
Be multi-AZ without inter-AZ traffic
We have updated HSDO so each HAProxy only sends requests to USP origins of the same AZ.
And the Network Load Balancers still send traffic to the HAProxys, on multiple AZs.
Removing inter-AZ traffic was not that much work and we quickly saw the difference: 45% cost savings.
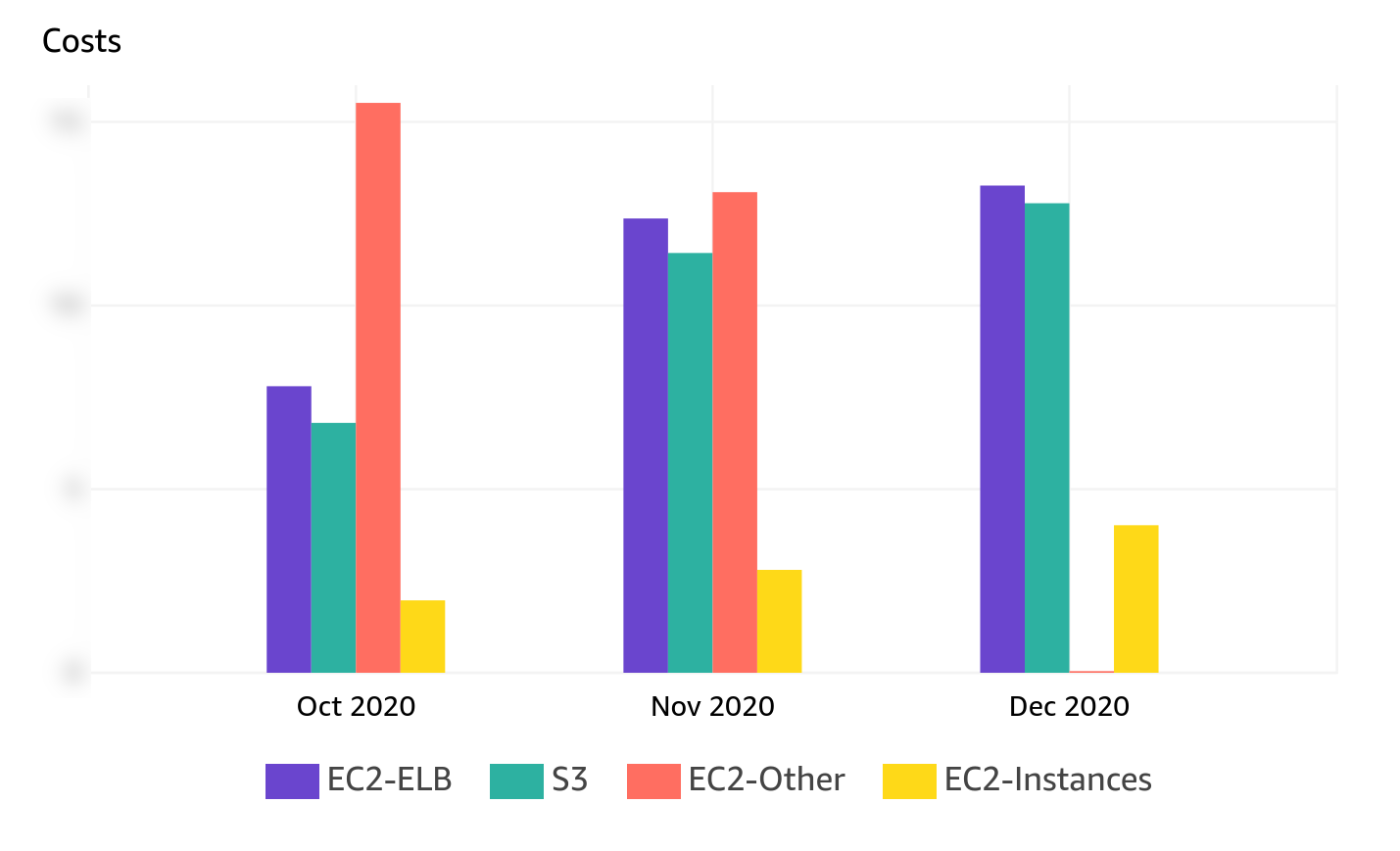
We can see on the picture above that the EC2-other costs (in orange) have disappeared in December.
The work on version 3 began shortly after the start of our cloud migration.
We were still migrating on-prem to the cloud when we put V3 on prod. That’s why you can see all costs have increased from October to December: we’ve doubled the number of viewers during the period.
Mono-AZ AutoScalingGroups
We have also replaced the multi-AZ AutoScalingGroups by several mono-AZ ones. It gives us a finer scaling that corresponds to the real needs in each AZ. The randomness of the round robin and client requests means that, from time to time, one AZ receives a significantly higher load than another.
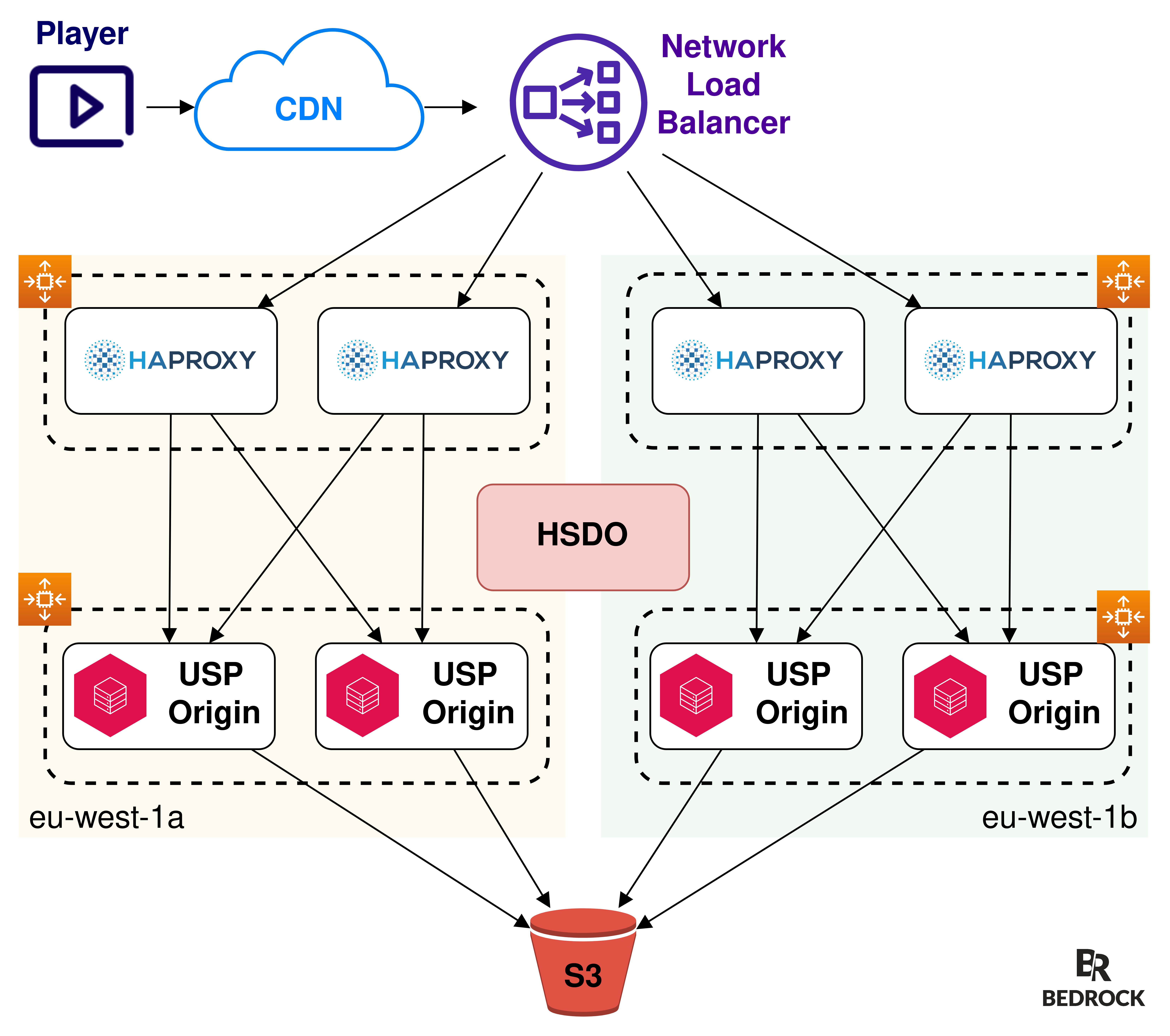
Since the NLBs are using a Round Robin algorithm, each HAProxy can receive traffic for any video. Now that the HAProxy servers of an AZ only send traffic to the USP origins of the same AZ, everything that is cached exists in as many copies as we have configured of AZs.
It makes us all the more resilient to an AZ failure.
Optimizations
Since V3, we have not made any major architectural changes. However, some optimizations were necessary.
Adapt HAProxy config for EC2 bandwidth throttling
On AWS, an EC2 instance has a baseline network capacity and a burst capacity (see UserGuide).
Baseline capacity is the network bandwidth you can consume all the time.
The Burst capacity is what you may be able to consume temporarily before being throttled to the baseline capacity.
In the EC2 presentation, the value “Up to” refers to the burst.
Less visible in the EC2 documentation, one can find the baseline capacity for each instance type (which is public knowledge since July 2021).
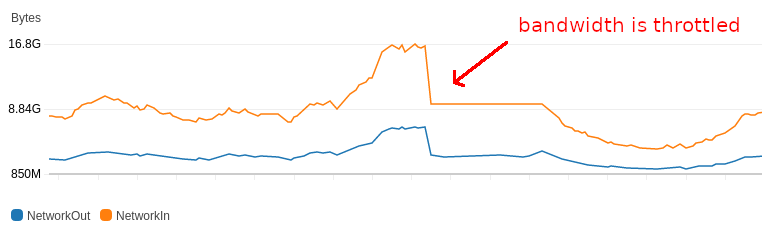
For example, c5.large instances have a network bandwidth Up to 10Gbps (burst) but only 0.75Gbps baseline bandwidth.
Troubles start when HAProxy sends a little more traffic to one instance than to the others: USP origin’s bandwidth may be throttled at some point… And we will observe poor performance or even service interruptions of this server.
We added observe layer7 to the default-server in our HAProxy backends, to remove servers returning HTTP error codes (5xx) from its load-balancing.
We also added the retry and redispatch options, which allow to retry a request sent to an unhealthy server on a healthy server. It’s not optimal for the cache, but what matters is that a client’s request is successfully answered.
We observed that with throttled bandwidth, the connection time from HAProxy to a USP server increases dramatically.
So we’ve also reduced timeout connect to 20 milliseconds.
Highlights of our HAProxy configuration:
defaults
timeout connect 20ms
retries 2
# We do not use "all-retryable-errors" because we don't want to retry on 500,
# which is an USP expected error code when it goes wrongly
retry-on 502 503 504 0rtt-rejected conn-failure empty-response response-timeout
option redispatch
timeout server 2s
default-server inter 1s fall 1 rise 10 observe layer7
Now, if a USP origin throttles on its network bandwidth or if there is a degradation of service, HAProxy will immediately redispatch the request to another server.
We are working on adding an agent-check, so that the weight of the servers in HAProxy can be directly defined by an USP origin, if it detects that its bandwidth is throttled.
Adjust the hash balance factor to correctly trigger scaling
Our scaling depends on the average server utilization in an AutoScalingGroup. If a few servers are overloaded but the majority is not doing anything, we don't scale.
But all contents on our platforms are not equally popular. This affects Consistent Hashing which would result in few servers receiving way more traffic than others. Few servers would be overloaded and the majority would not do much.
Here is an example in a load test:
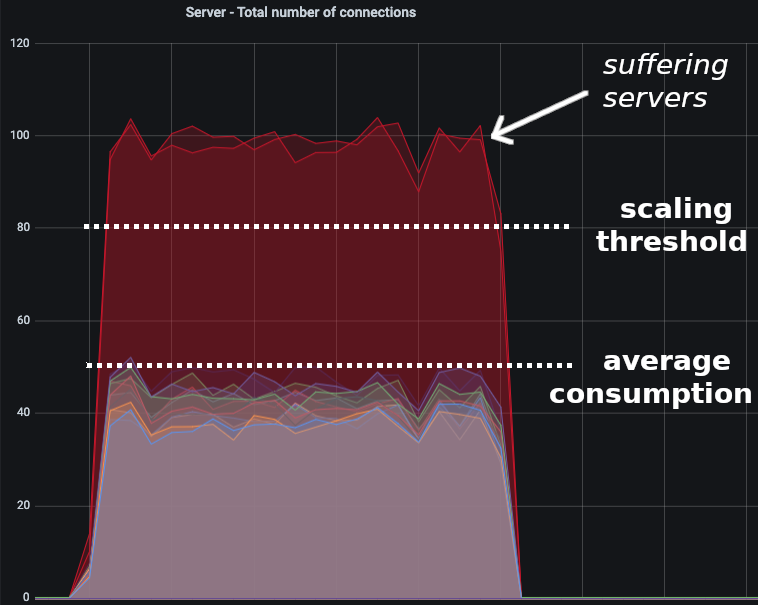
We want to benefit from Consistent Hashing while being able to scale on average consumption. This is what Consistent Hashing with Bounded Loads allows: to benefit from Consistent Hashing, while balancing load.
The Bounded Loads are controlled by the hash-balance-factor option in HAProxy.
According to the doc:
<factor> is the control for the maximum number of concurrent requests to
send to a server, expressed as a percentage of the average number
of concurrent requests across all of the active servers.
We played the same load test, once using classic Consistent Hashing, a second time using bounded loads:
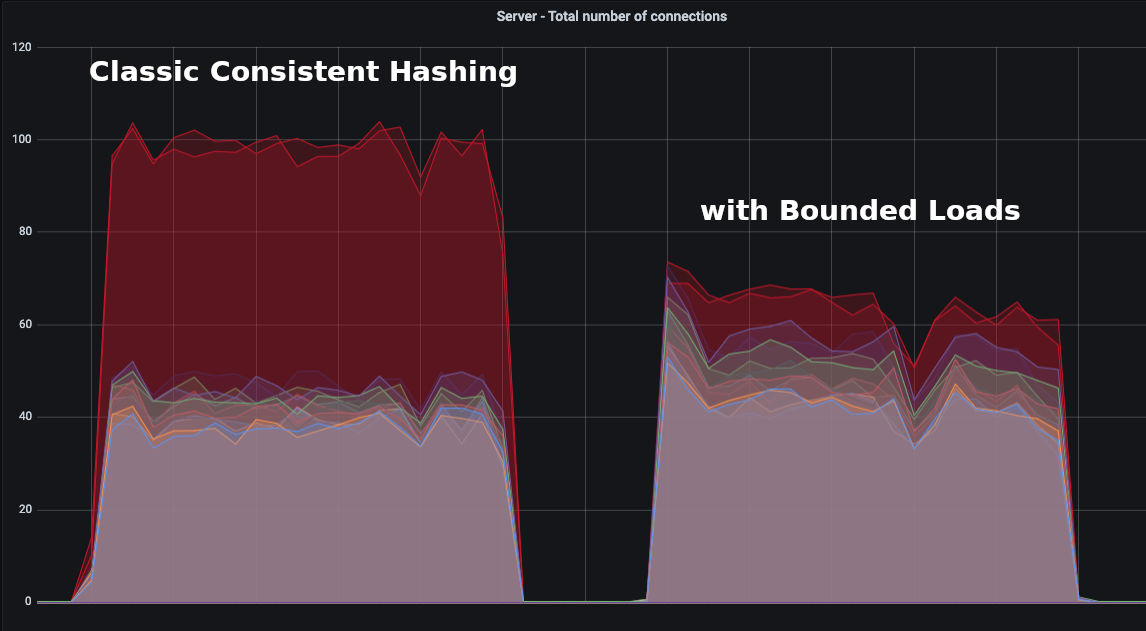
We did dozens of load tests before finding the best value for our use: 140.
For each load test, we looked at the evolution of:
- Nginx Cache Hit Ratio
- Number of requests to S3
- HAProxy Backend retries and redispatches
- HAProxy backend 5xx response codes
- Free disk space on USP origins
Our configuration of the Consistent Hashing with Bounded Loads remains simple:
backend usp-servers-AZ-C
balance hdr(X-LB)
hash-type consistent sdbm avalanche
hash-balance-factor 140
Thanks to Consistent Hashing with Bounded Loads, our cache is optimized without impacting our autoscaling.
There may be contents much more solicited than others, the load will be balanced and our autoscaling will be activated.
Conclusion
We migrated our video delivery to the cloud, moving from static servers to an end-to-end auto-scaling and multi-AZ infrastructure. We are now able to handle very high loads, which we could not do on-premise.
We had the opportunity to review our architecture three times, within a few weeks of each other, even though the migration had begun.
The v3 is not perfect, but it is quite well optimized, reliable and scalable.
We are thinking about V4 and saving 20% of the costs by removing the NLB. We also identified some possible improvements, adding cache on HAProxy for example, or using HAProxy Agent Check so that the weight of the servers in HAProxy is driven directly by the servers, using the Amazon metrics on network performances. Another promising performance improvement could be to use HAProxy on ARM as Graviton type instances offer significant discounts, it will be worth testing.
In parallel, we also invest time on CMAF which is for us, the long-term objective.
Special thanks to all my colleagues at Bedrock Streaming and members of Unified-streaming, for re-re-re-and-rereading this blog post. ❤️