
Bedrock Streaming is a company that sells a white labeled streaming and live platform. Our customers are media groups, TV channels, and streaming companies. Our goal is to deliver a state-of-the-art streaming platform to our customers.
To achieve this goal, we have our own Content Delivery Network (CDN), made of several bare metal servers racked in our Data Centers. Those servers run Nginx and are designed to output hundreds of Gbps (several tens of Pb per month) to end-users. We use them to cache video content at our infrastructure’s edge.
This increases efficiency of the platform 96 times out of 100, as video traffic doesn’t have to flow all the way through our infrastructure, and improves user experience as it serves video faster. Also, it diminishes the cost of our Video On Demand (VOD) infrastructure as we need less servers in VOD Stack.
This in-turn increases end-users (clients of our customers) satisfaction with the service.
Who needs to ingest 400GB of logs per hour anyway?
Every time someone watches a video, it generates traffic on our CDN, resulting in a lot of access logs. Without filtering, it averages to 400GB uncompressed logs per hour.
This is why, at first, we chose to not log 2XX or 3XX HTTP codes. We had too many of them, and we considered them not as worth it as 4XX and 5XX. The 4XX and 5XX can be especially useful for debugging a particular situation or, from a broader perspective, improving the user experience.
This was the kind of Nginx configuration we had deployed:
map $status $loggable {
~^[23] 0;
default 1;
}
access_log /path/to/access.log combined if=$loggable;
Giving autonomy for all teams on logs
At the end of 2021, the finance team approached us with a challenge: how to bill our customers based on their end-users CDN usage? This was in fact a need we already anticipated, we tried the nginx module Traffic_accounting, but it did not satisfy us fully. This module calculates and exposes metrics on-the-fly, which is CPU and memory intensive, especially above 50Gbps of traffic per server.
We also had another objective that wasn’t addressed with the nginx module. We needed to give autonomy to QA, Video, Data, and Finance teams. We wanted to allow them to use CDN logs when they needed without having to ask for it, and ideally in a practical and unified way.
The company philosophy states that we are user obsessed and that we do not finger point. We work as a team to offer the best user experience, this is why we make all our logs available to all teams. We didn’t come around to do it for the CDN as the volume of logs was too much of a constraint.
Technical Solution
At Bedrock, we like to keep things simple. We think our CDN main mission is to serve video as efficiently as possible. Our CDN’s servers can’t keep PetaBytes of logs on their disks. This is why we chose to output logs to Amazon S3.
The real benefit to using S3 is that you can easily plug it into Glue and Athena which allows you to request TeraBytes of data easily.
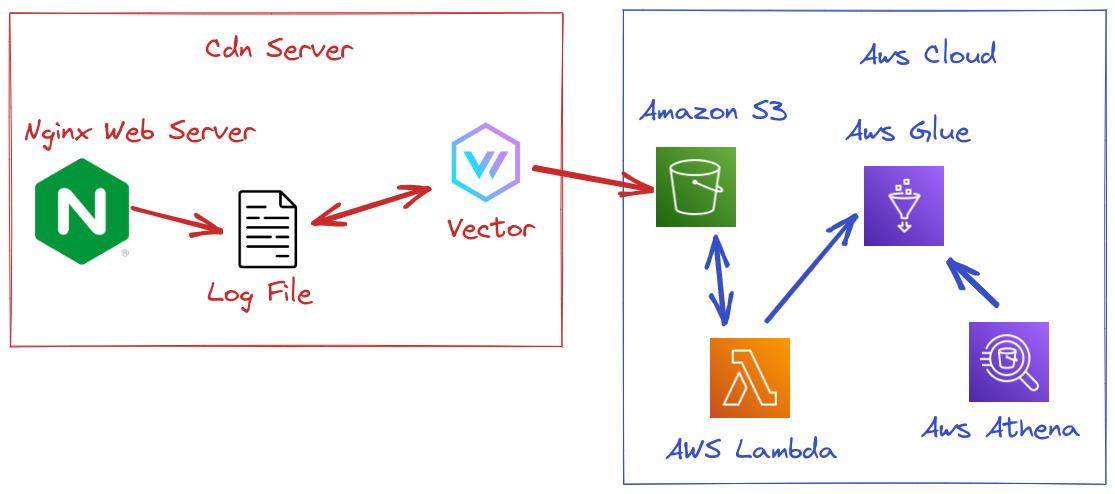
Sending logs to S3: Vector
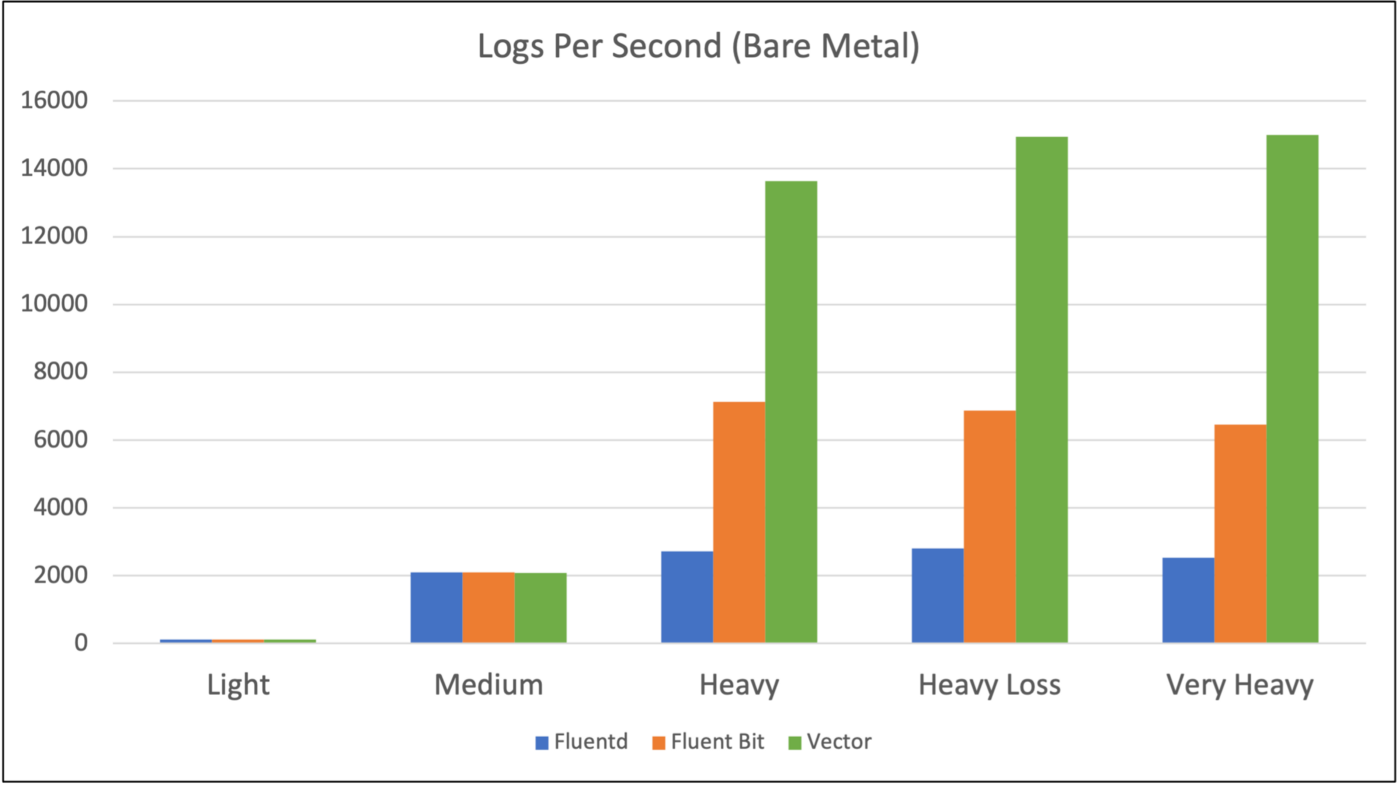
To send logs from our CDN servers to Amazon S3 bucket, we had many options, but chose to test two approaches: Fluentd and Vector. Fluentd is the legacy one, and Vector the new rusty one.
After a quick evaluation, we decided to go with Vector as it seemed more memory efficient and output more Logs Per Second under heavy load than Fluentd.
We have Nginx and Vector installed on the CDN servers. Nginx now outputs all the access logs to a file. Vector reads the file, compresses logs to GZIP format and every 10Mb sends the logs to S3. Nginx may generate at peak 600GB of logs; we only send 10GB.
Those logs are then locally cleaned by Logrotate.
Storing logs: S3
We chose to store logs on an S3 bucket. We figured it was the most scalable and time efficient. S3 buckets can grow to PetaBytes easily. It is a few terraform lines away, this is convenient as we handle all our infrastructure with Terraform.
We configured our bucket to use several lifecycle policies. One to automatically clean logs after 365 days, another to remove incomplete uploads, and another one to immediately remove files with a delete marker. Also, we configured the storage class in intelligent tiering mode to store logs according to their access frequency.
This will permit us to diminish the cost of our S3 bucket and not have an ever-increasing S3 bill.
Partitioning logs on S3: Lambda stack
Once logs are stored in S3 bucket, we need to classify and sort them in order to extract valuable intel. At Bedrock, we already use a modified version of a lambda stack, that does just that. Originally designed for Cloudfront, we have been using it also for Fastly and now for our Private CDN. You can find the original version at AWS Sample Github.
We have 2 different parts in this lambda stack.
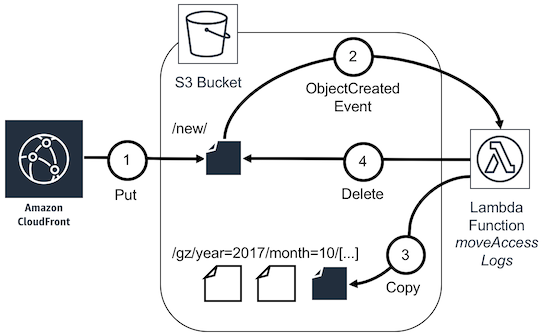
The first part is called by S3 Event when a new file is pushed to a specific path. This lambda moves the file to a path assigned per server and per hour. This way, logs are stored for each server, each month, each day and each hour in a separate prefix.
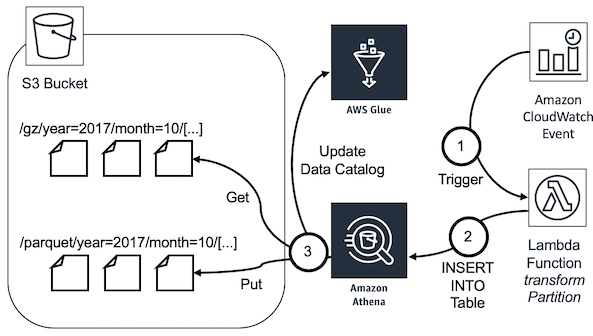
Then, another lambda transforms logs into Parquet format. Parquet is an open source format from the Apache Foundation. It is commonly used in big data. It takes up little space and is very effective.
We chose to use AWS glue in order to create a database of our logs. The columns of the table are based on our log format. We can then request everything we want in Athena.
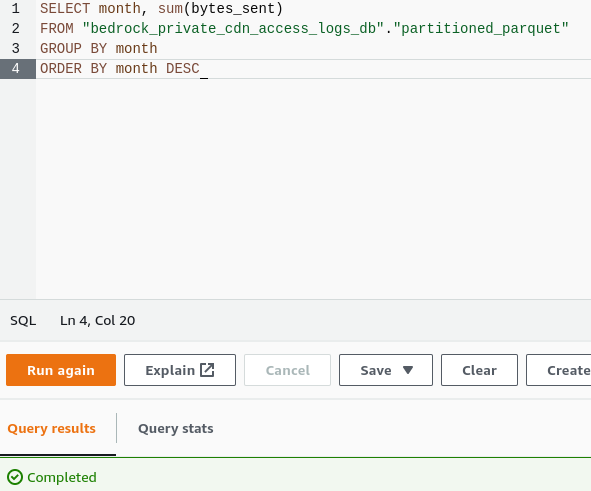
We are now capable of extracting the bytes sent from a particular virtual host and sum it over a month for all CDN servers to bill our customers. Those logs are now available for all the teams who may need them to improve their application or to debug an issue they are facing.
Conclusion
We chose Vector to transport our private CDN logs to an S3 Bucket. Then, we chose to reuse an AWS Stack using Lambda and Glue to extract information from these logs, asynchronously. This stack is used in production for several months on other projects. All the teams that needed to extract value from our CDN logs are now autonomous to do so. We are now able to bill our customers based on their CDN usage.