Velocity Barcelone, seconde journée
Deuxième jour de conférence avec un programme encore plus chargé et quelques conférences alléchantes repérées au préalable.
Morning Keynotes
Upgrading the Web: Polyfills, Components and the Future of Web Development at Scale - Andrew Betts (FT Labs)
L’orateur fait remarquer que de nombreux systèmes existent pour packager et gérer les dépendances des applications backends, mais rien n’est disponible pour les composants webs. Il nous a présenté le projet Origami qui permet de réutiliser massivement des composants HTML.
Slides : the Future of Web Development at Scale
Troubleshooting Using HTTP Headers - Steve Miller-Jones (Limelight Networks)
Slides : Troubleshooting Using HTTP Headers
Un employé de Limelight nous a présenté comment l’ajout de headers dans une requête pouvait renvoyer des headers supplémentaires dans la réponse HTTP. Cela peut être utile pour débugguer et analyser un incident. Cette présentation nous a rappelé, qu’en interne, nos gentils ops nous permettent déjà de faire ce genre chose sur nos proxy cache.
{kind=link}
Monitoring without Alerts - and Why it Makes Way More Sense than You Might Think - Alois Reitbauer (ruxit.com)
Alois Reitbauer a évoqué la solution Ruxit développée depuis plus de trois ans. Cette solution consiste à installer un agent sur vos serveurs qui va automatiquement détecter des anomalies statistiques et corréler cette information avec d’autres déviations dans le but de trouver la root cause d’un incident.
Beaucoup d’autres solutions de ce genre existent (et la plupart étaient dans le salon des sponsors). Nous n’avons pas été totalement convaincu de leurs capacités à détecter des root cause, mais elles sont toutes assez intéressantes et matures.
Lowering the Barrier to Programming - Pamela Fox (Khan Academy)
Pamela Fox nous a présenté l’initiative code.org, dont le but est de promouvoir l’enseignement de l’informatique (bon, apparement seulement aux US).
Elle a également donné quelques conseils si on veut s’investir dans l’enseignement de l’informatique à destination des plus jeunes. Par exemple créer un code club.
Slides : Lowering the Barrier to Programming
Velocity at GitHub - Brian Doll (GitHub)
Brian a fait une présentation très … minimaliste. Il est revenu rapidement sur 7 ans de développement à GitHub et comment ils sont venus à développer l’Enterprise Edition. Il a évoqué différents problèmes que certains de leurs clients avaient et notamment avec l’utilisation de GE en environnement cloud.
Il a donc annoncé le lancement de GitHub Enterprise 2.0 qui fonctionne maintenant sur AWS (et un changement de la grille tarifaire) !
J’ai profité d’un instant avec lui pour lui présenter GitHubTeamReviewer (un outil interne open-sourcé). Il était enchanté de découvrir ce qui avait été fait avec l’API de Github. Il a indiqué que l’entreprise travaillait actuellement sur des vues permettant de pallier aux problèmes résolus par GitHubTeamReviewer.
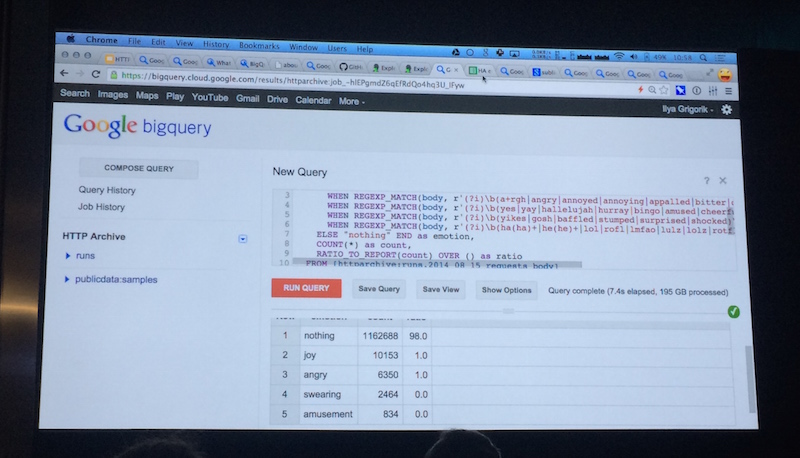
HTTP Archive and Google Cloud Dataflow - Ilya Grigorik (Google)
Ilya Grigorik a présenté https://bigqueri.es/, un outil permettant d’interroger HTTP archive. La nouveauté est que le body des requêtes est maintenant conservé et que l’on peut l’analyser. Un engine Javascript a été intégré au SQL de bigqueries permettant de faire des requêtes très puissantes.
Pour ceux qui ne voudraient pas se plonger dedans, beaucoup de recherches faites par d’autres utilisateurs sont disponibles et abondamment discutées (exemple).
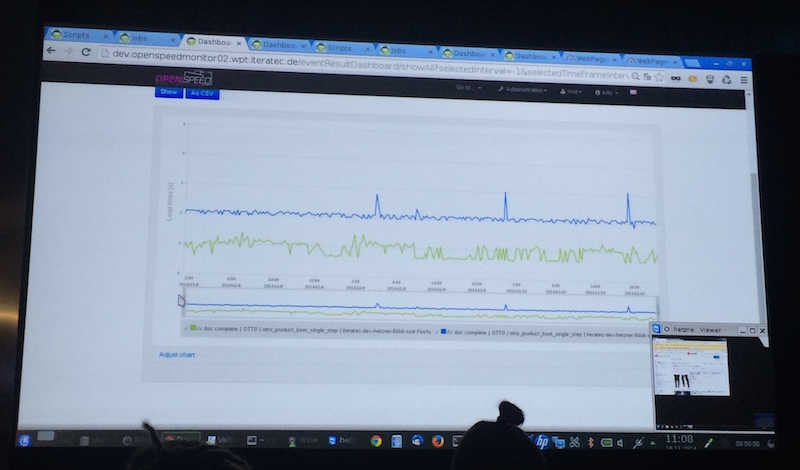
Webpagetest-automation 2.0 - Nils Kuhn (iteratec GmbH), Uwe Beßle (iteratec GmbH)
Webpagetest est un outil formidable mais il est difficile à automatiser. Les orateurs ont présentés un outil pour le faire, permettant donc de réaliser une mesure continuelle de la webperf avec un parcours utilisateur complet - démonstration à l’appui.
Leur travail est disponible sur GitHub sous licence Apache : https://github.com/IteraSpeed/OpenSpeedMonitor. Un grand merci <3 ! (à 10 minutes sur la vidéo).
Etsy’s Journey to Building a Continuous Integration Infrastructure for Mobile Apps - Nassim Kammah (Etsy)
Une parmi les très nombreuses conférences Etsy sur la Vélocity (le moment de renouveller les conférenciers ?). Nassim Kammah nous a expliqué comment Etsy délivrait ses applications iOS.
La livraison des applications sous iOS est au même stade que la diffusion des logiciels via CD-ROMs. Partant de ce constat un système de build (avec 25 mac-minis derrière) a été mis en place à chaque commit sur le master. On ne peut pas délivrer une version de l’application tous les jours aux clients, mais on peut le faire pour les employés (and eat your own dog food) !
Il y a également un système de gamification, autour de l’application livrée journalièrement, afin de motiver tout le monde à trouver des bugs.

Des tests unitaires sont mis en place, ainsi que des tests fonctionnels avec AppThwack. Il est intéressant de constater qu’ils n’attendent pas, pour les tests fonctionnels, une réussite à 100% de la suite mais une tendance positive.
Les équipes ont également mis en place des testing dojos dans lesquels les ingénieurs QA encadrent des salariés d’Etsy et testent à fond les applications.
On peut retrouver tous les éléments de cette conférence sur le blog technique d’Etsy.
Recycling: Why the Web is Slowing Your Mobile App - Colin Bendell (Akamai)
Pourquoi recycler nos contenus pour les applications mobiles ?
- accélérer le time to market.
- réduire le risque
Les APIs encouragent le recyclage.

Colin Blendel nous encourage à utiliser les mêmes recettes que pour les navigateurs web et à en ajouter d’autres :
- gérer le pool de connexions en groupant les appels par domaine (quitte à les passer séquentiellement, par exemple, si des cookies sont utilisés),
- surveiller les packet eaters (headers inutiles, Set-Cookies répétés),
- setter correctement Content-Type sur des types standard (les exemples de content-type tirés des logs d’Akamai sont assez drôles, comme par exemple test/binary ^^ !),
- faire un minimum de redirections,
- fragmenter son cache au minumum (quitte à calculer des clés plus consistantes coté client),
- ajouter du cache (Max-Age: 30s c’est à peu près du temps réel et ça change tout pour un CDN),
- préfetcher les urls présentes dans les retours d’API, car on va surement en avoir besoin immédiatement après,
- ne pas hésiter à mettre CRUD au placard et merger plusieurs appels API en un seul ; il faut trouver une balance efficace pour bien gérer la webperf.
Une présentation dense et vraiment intéressante !
Slides : Why the Web is Slowing Your Mobile App
Breaking News at 1000ms
Le Guardian est un journal Anglais présent sur le web et sur tout type de device. Ils ont récemment fait une refonte de leur site pour passer à une version Responsive avec pour challenge d’afficher son contenu en moins d’une seconde.
Le Guardian c’est 110 000 utilisateurs, 7000 différents devices. L’ancien site avait un début de rendu en 8 secondes pour un affichage complet en 12. Avec la nouvelle version le site s’affiche en 1 seconde et le chargement complet au bout de 3. Quelles sont les principales optimisations ?
Pour commencer, il faut charge le contenu important pour l’utilisateur en premier, à savoir le menu, l’article, et le widget d’article populaire. Le reste du contenu sera chargé dynamiquement en JS.
En ce qui concerne le css, c’est la même chose. Les CSS importantes (critiques) qui concernent l’article et le rendu global sont intégrées inline. Ainsi, nous n’avons pas de blocage du rendu de la page. Le reste des css est chargé via Javascript. Avec ce système, on gagne au moins une demi-seconde sur le début d’affichage du contenu. Pour gagner en fluidité pour les prochains affichages, le css est stocké en localStorage. On gagne ainsi des ressources pour les prochains chargements.
Pour les fonts ? C’est la même chose, elles sont mises en cache dans le localStorage pour supprimer de nouveaux chargements.
Enfin le gros morceau : les images ! Elles sont chargées de façon asynchrone en lazyloading. Cela permet de ne pas bloquer le rendu principal de la page.
En complément, ils ont mis en place des outils, notamment pour monitorer dans Github la taille des Assets afin de vérifier qu’il n’y a pas de grosses variations.
Avec ces optimisations et un système de Proxy qui va gérer les données mises en localStorage, le site peut même être accessible en mode offline.
Offline-first Web Apps
Matt Andrews nous présente comment rendre une application web disponible Offline.
Plusieurs contraintes peuvent nous pousser à avoir besoin d’une app (signet d’accueil) disponible même sans connexion. Que ce soit un article dans le métro ou une carte au milieu de nulle part sans connexion, il y a une réelle attente utilisateur.
Premièrement, il faut activer AppCache en précisant qu’il faut faire un petit Hack pour qu’il soit vraiment utile (voir slide).
Ensuite l’utilisation de plusieurs outils nous permet d’arriver à nos fins :
- Utilisation de FetchApi : Il permet de remplacer nos appels Ajax avec une fonction succès , d’erreur et les Promises pour charger le contenu, ou lire le cache en cas d’absence de connexion.
- Cache API : Il permet de choisir des Url a mettre en cache. Ainsi que de forcer le contenu de ces urls dans le code.
- Service Worker : Il permet d’intercepter les events de chargement pour ensuite appeler le système de Cache API.
Toutes ces optimisations nous permettent d’accéder au site en Offline. Mais ces optimisations nous permettent aussi d’optimiser le chargement de nos pages puisqu’on limite le nombre d’appels HTTP avec la mise en cache de certaines ressources.
Look, Ma, No Image Requests!
Pamela Fox nous présente comment elle a optimisé les images d’un site internet.
La première astuce est de compresser ces images au maximum. Il existe des outils online comme le site TinyPng qui compresse vos images et vous permet de les télécharger directement.
Deuxième astuce, mettre les images dans les css en base 64. A noter qu’il existe des outils javascript qui effectuent la conversion dans les css à l’aide d’un petit commentaire en bout de ligne (voir les slides de présentation).
Troisième solution : Les Fonts ! Pour remplacer les petites images et surtout pour remplacer les sprites qui ne sont pas forcément adaptés, vous pouvez utiliser des Fonts. L’avantage des fonts est qu’elles peuvent s’adapter facilement en taille et en couleur … Des outils existent déjà pour les générer : Font Awesome.
Autre astuce, le differ de chargement des images. Pamela nous propose son outils javascript, qui va permettre de vous simplifier les chargements. Il est aussi possible de ne charger que les images présentes à l’écran et de charger les suivantes lors du scroll. (lazyload).
Pour les vidéos la même astuce est possible. Puisque les vidéos sont à présent chargées dans des iFrame, leur contenu peut être chargé de façon différé. Attention, il ne faut pas remplir le href par une url blank, sinon on perd en temps de chargement.
Microservices - What an Ops Team Needs to Know
Slides: Microservices - What an Ops Team Needs to Know

Le buzzword est lâché. Le propos n’était pas ici de troller autour de la notion de micro-services, de l’implémentation ou de leur utilisation, mais plutôt du changement que cela implique pour les équipes d’exploitation.
Souvent considéré comme le goulot d’étranglement de la chaîne de mise en prod, l’exploit’ regarde les architectures de micro-services avec circonspection : en plus d’avoir des dépendances entre eux, les composants sont mis à jour indépendamment et régulièrement, on peut donc vite tout casser en prod. Pourtant en fournissant des services de bases et des outils aux équipes de développement, on peut augmenter leur autonomie et la disponibilité des infras.
Cela passe par:
- automatiser les VMs ou les containers en prod comme en dev
- un système de métriques “As a Service” (similaire à graphite / statsd)
- un service de log central (logstash/heka/fluentd)
- un outil de déploiement (capistrano/deployinator)
Ces outils et services ainsi fournis vont permettre à l’exploitation de se concentrer sur des problématiques plus complexes. En effet les microservices ont besoin d’outils de diagnostics plus poussés (on citera au passage Zipkin), d’alerting et de monitoring spécialisés par exemple.

Qui dit droits, dit devoirs, et là je paraphraserai notre orateur Michael Brunton-Spall:
Give developers pagers too !
Developers should be exposed to the pain they cause
Cela s’inscrit totalement dans le mouvement “You build it, you run it”, où les équipes de développement sont responsables de leur code depuis la conception jusqu’à la maintenance en production.
It’s 3AM, Do You Know Why You Got Paged ?
Slides: It’s 3AM, Do You Know Why You Got Paged ?
Ryan Frantz nous a rappellé quelques éléments de bon sens concernant les alertes:
- un contexte: quel hôte ? serveur ? service ? l’impact front / back ?
- l’historique de l’alerte et de la métrique: état de la métrique il y a 5min, 15min, 1 jour, 1 semaine, combien de fois a sonné l’alerte aujourd’hui ?
- la raison d’être du check (rédigée par le créateur du check)
- des couleurs et mise en forme permettant de trouver visuellement l’information le plus rapidement possible (rappel il est 3 heure du matin, et peut être daltonien, pensez donc bien à vos codes couleurs)
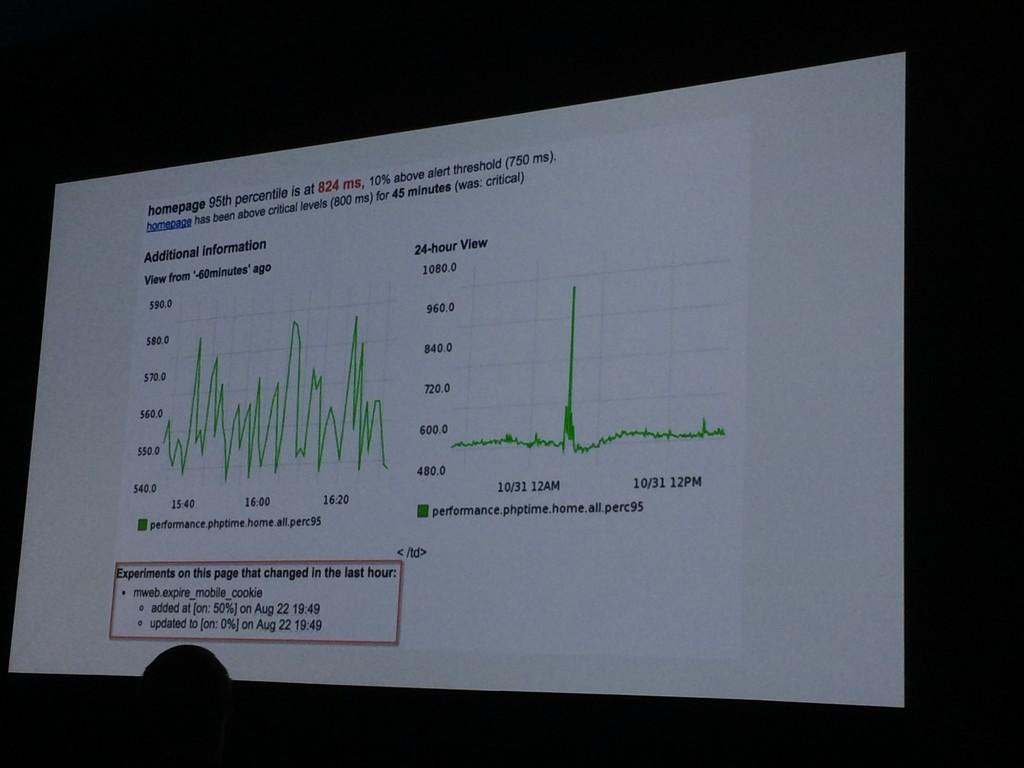
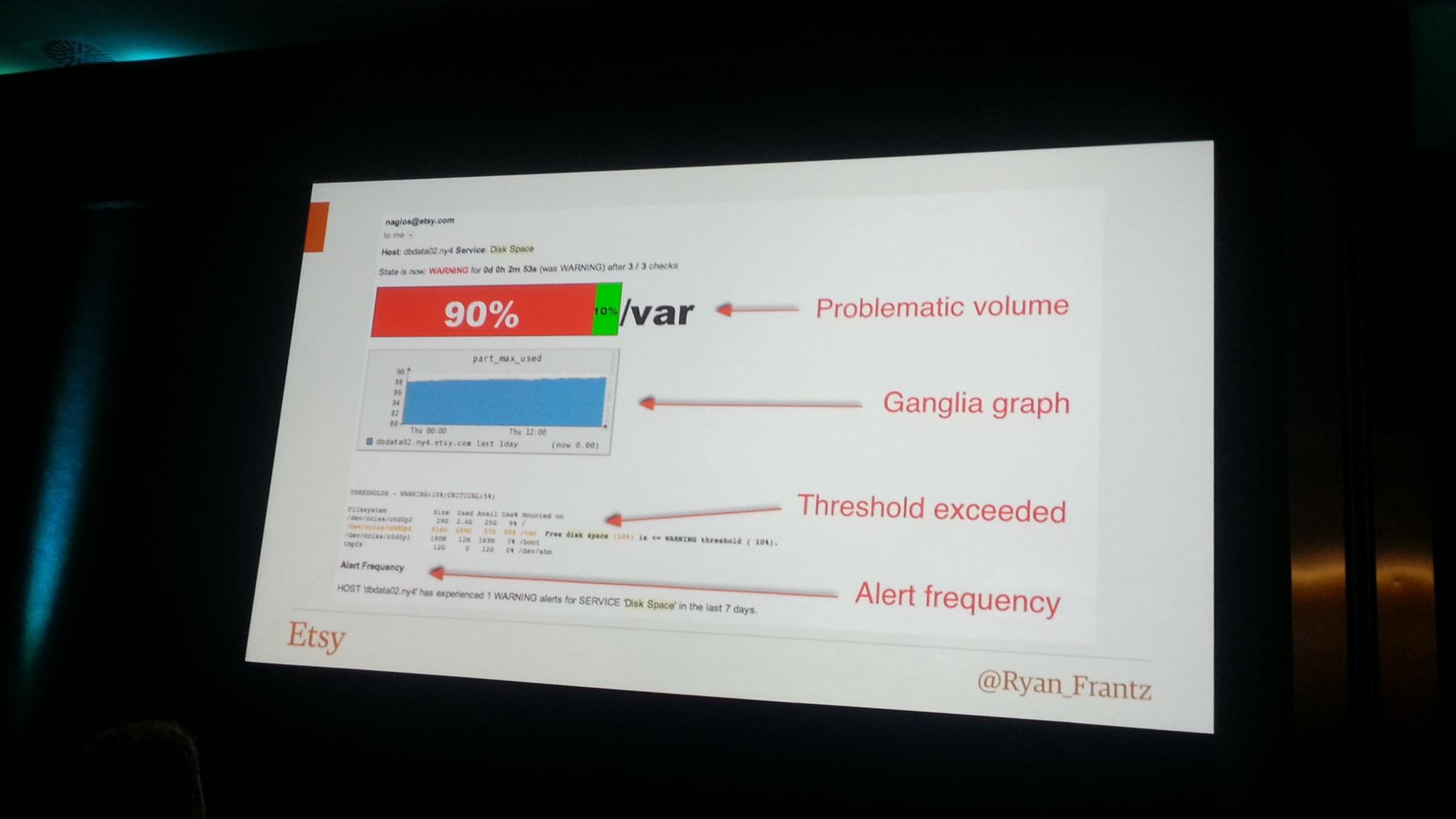
Seule une alerte critique doit vous faire lever à 3H du matin, un volume disque à 80% plein n’est pas réellement grave, cependant si son taux de remplissage est passé de 1% par heure à 300% par heure, cela peut devenir problématique.
Ryan nous a ensuite présenté nagios-herald. Ce plugin nagios permet de multiplexer une alerte dans différent services (cf schéma) ci dessous.
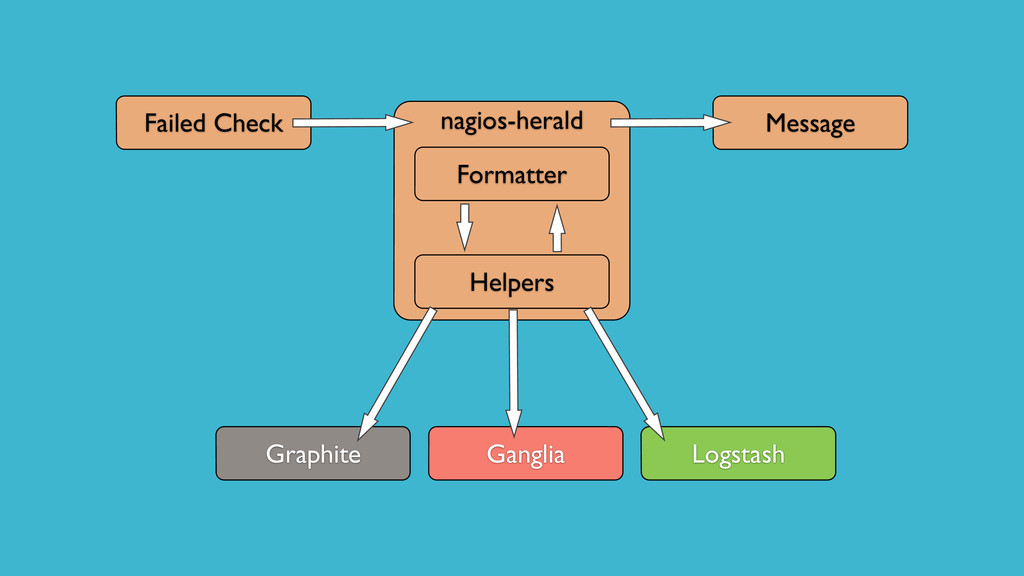
Pour ma part je préfère Sensu qui intègre de base ce type de mécanisme. On peut affecter à une alerte un groupe de handlers (alerte hipchat + graphite + logstash par exemple)
Customizing Chef for Fun and Profit

Slides: Customizing Chef for Fun and Profit
En suivant les étapes d’application d’une recette Chef, Jon Cowie a distillé son savoir sur la personnalisation de Chef.
Il nous a par exemple démontré qu’il était très simple de développer son propre plugin ohai et ses propres handlers.
J’ai apprécié le passage sur la gestion des événements Chef, en effet la sortie en ligne de commande n’est qu’une des façons de récupérer les logs, les événements sont basés sur un système de pub/sub, on pourrait très bien imaginer la publication en live stream dans un redis ou autre.
Par ailleurs Jon vient de publier un livre sur le sujet: O’Reilly - Customizing Chef
Mega quiz Velocity
Perry Dyball et Stephen Thair avaient préparé un quiz interactif avec les participants à la conférence. Des questions diverses et variées défilaient sur le grand écran et une application web permettaient à chacun d’y répondre. Un moment fun animé par deux animateurs survoltés. Malheuresement il semble que l’application n’aient pas tenu la charge et personne n’a pu voté après la seconde question (la prochaine fois ils devraient nous confier le projet :) ), mais un système de fallback a été prévu, basé sur des feuilles de papier de couleur à brandir bien haut pour répondre aux questions.
merci le papier ! :)

Conclusion
Fin des conférences et direction les soirées offertes par Facebook (où nous avons pu discuter avec Santosh Janardhan, responsable des infrastructures de Facebook ^^ !) et Dyn.
Le résumé de la première journée est également disponible.