At Bedrock, we recently migrated our Kubernetes clusters from AWS VPC CNI to Cilium—with zero downtime. By leveraging Blue-Green canary with HAProxy for progressive traffic shifting and Consul for dynamic configuration updates, we achieved a seamless transition to eBPF-powered networking.
You might wonder: why all this complexity around migration? Can’t you simply install Cilium in place of VPC CNI with a straightforward kubectl apply?
But here’s the key insight: this isn’t just about Cilium. Whether you’re migrating to Cilium, Karpenter, the AWS Load Balancer Controller, Keda, or any other core infrastructure component that introduces breaking changes, the challenge remains the same. You need to transition from one set of tools to an incompatible version or alternative without any downtime and with the ability to rollback in seconds if issues arise.
The Blue-Green canary clustering approach we’ll describe is a reusable pattern for handling any breaking change in your Kubernetes infrastructure. By creating a parallel cluster with the new configuration and progressively shifting traffic, you gain complete control over the migration while maintaining zero-downtime guarantees.
Table of Contents
What about today?
Today in 2026, we are still relying on KOps managed Kubernetes cluster running on EC2 spot instances in private subnets at AWS. We needed to get more observability at our network layer on Kubernetes to have better insights about possible bottlenecks on our infrastructure or our ingresses implementation, but not only.
To have more insights on the fundamental differences between iptables with kubeproxy and eBPF there’s this very interesting blogpost from Isolvalent that we encourage you to check. It contains a lot of usefull informations.
What is Kube-Proxy and why move from iptables to eBPF?
Dig into live migration
With a clear understanding of why we needed to migrate to Cilium, the critical question became: how do you execute such a migration in production without any downtime? This chapter explores the deployment strategies we evaluated, our hybrid approach combining Blue-Green and Canary patterns, and the technical infrastructure we built using HAProxy and Consul to orchestrate the migration safely.
Handle live migration with zero downtime
Several strategies exist for achieving zero or near-zero downtime during migration. The two most common approaches are Blue/Green and Canary deployments. Each has distinct advantages depending on your infrastructure and risk tolerance. We evaluated both before selecting the approach that best aligned with our production requirements and operational constraints.
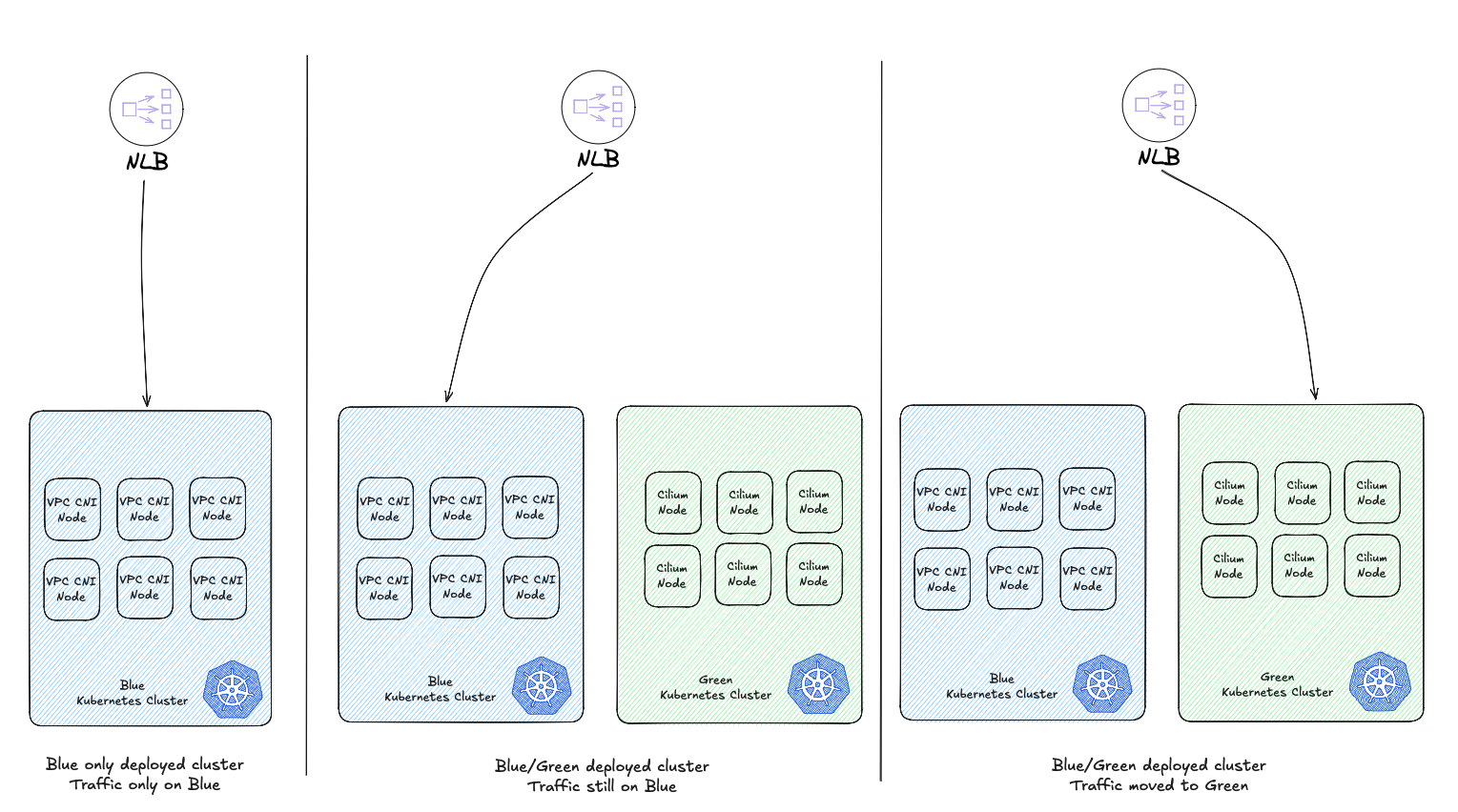
Blue/Green deployment
Blue/Green deployment is a strategy that improves application availability while minimizing downtime and risk. You deploy to two identical production environments: “blue” represents the current live environment, while “green” hosts the next version.
Once thoroughly tested in green, traffic switches from blue to green. This swift transition minimizes downtime and enables instant rollback if issues arise—simply revert traffic back to blue.
Canary deployment
Canary deployment takes a different approach by avoiding the need for duplicate production environments. Instead, you select a subset of servers or nodes to receive the new deployment first, serving as a testing ground before rolling out changes across the entire infrastructure.
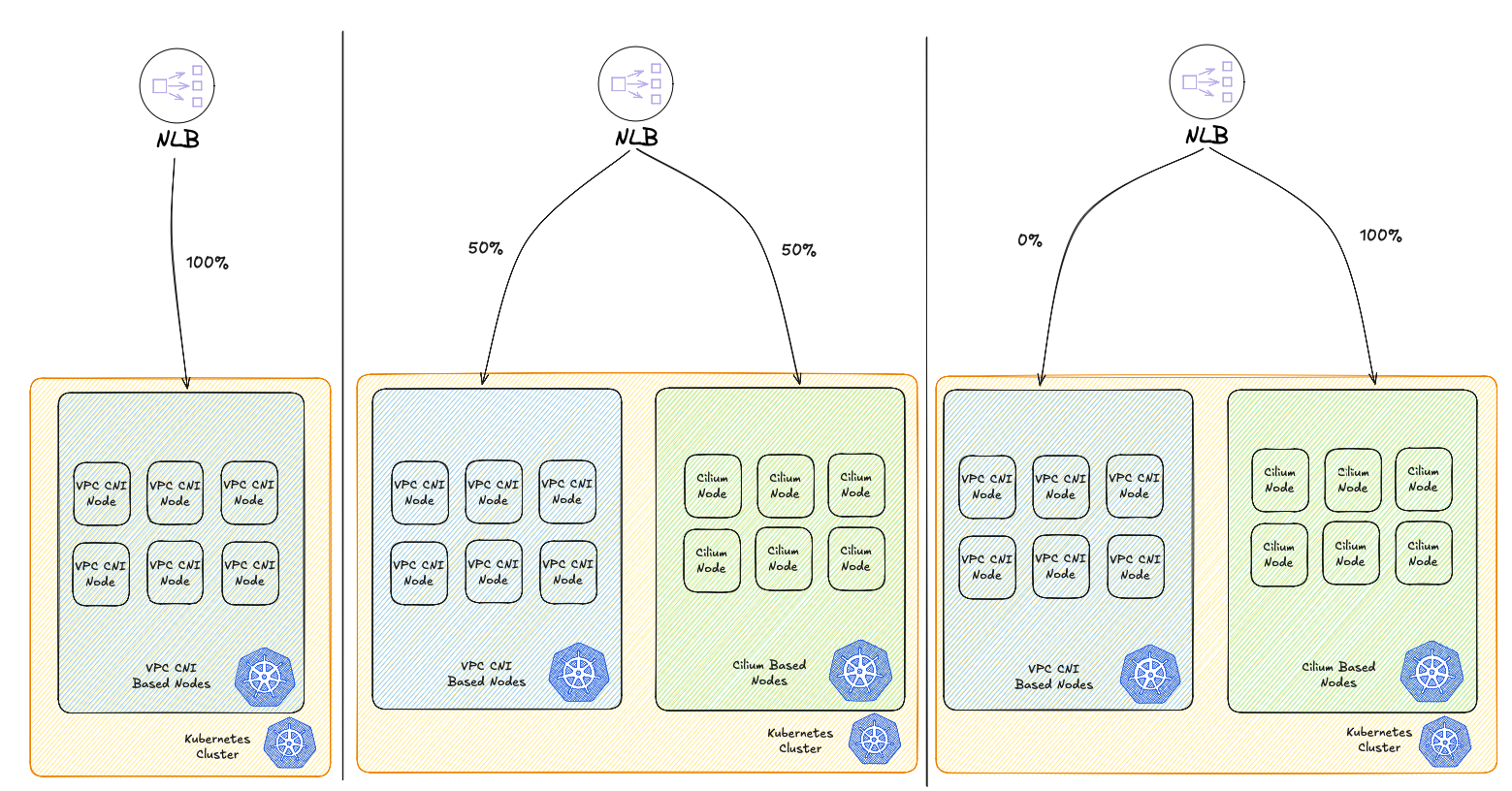
A typical canary deployment workflow using a load balancer looks like this:
- Your production infrastructure runs behind a load balancer with additional nodes kept in reserve.
- Deploy the new version to these spare nodes, which become your “canary” servers—the first to run the updated code in production.
- Configure the load balancer to route a small percentage of traffic to the canary nodes, exposing the new version to a limited number of users while monitoring for errors and gathering feedback.
- If metrics look healthy and no critical issues emerge, progressively increase traffic to the canary nodes until they handle 100% of requests.
HAProxy blue/green load balancing
At Bedrock, we opted for a hybrid Blue-Green Canary approach to handle our live migration. We still use HAProxy for reverse proxy needs—it works perfectly-fin on our side and we know it well. This made it the natural choice for orchestrating our migration to Cilium.
To avoid making an ON/OFF migration, we leveraged HAProxy to make a progressive switch to our new Cilium cluster. We deployed a new layer of load balancing and ASG with HAProxy in front of our Kubernetes cluster with pre-defined weights between our blue and green clusters. Our hybrid approach also gave us the flexibility to migrate traffic application by application rather than switching everything at once. By maintaining separate weight configurations for each API or service, we could independently control the traffic distribution for individual applications. This granular approach was a mandatory prerequisite to ensure stability and security throughout the migration.
We could start with less critical services, validate Cilium’s performance in production with real traffic, and progressively move more sensitive applications only after gaining confidence. If an issue appeared with a specific application on the Cilium cluster, we could immediately roll back just that service while keeping others on the new infrastructure—significantly reducing blast radius and risk compared to an all-or-nothing migration strategy.
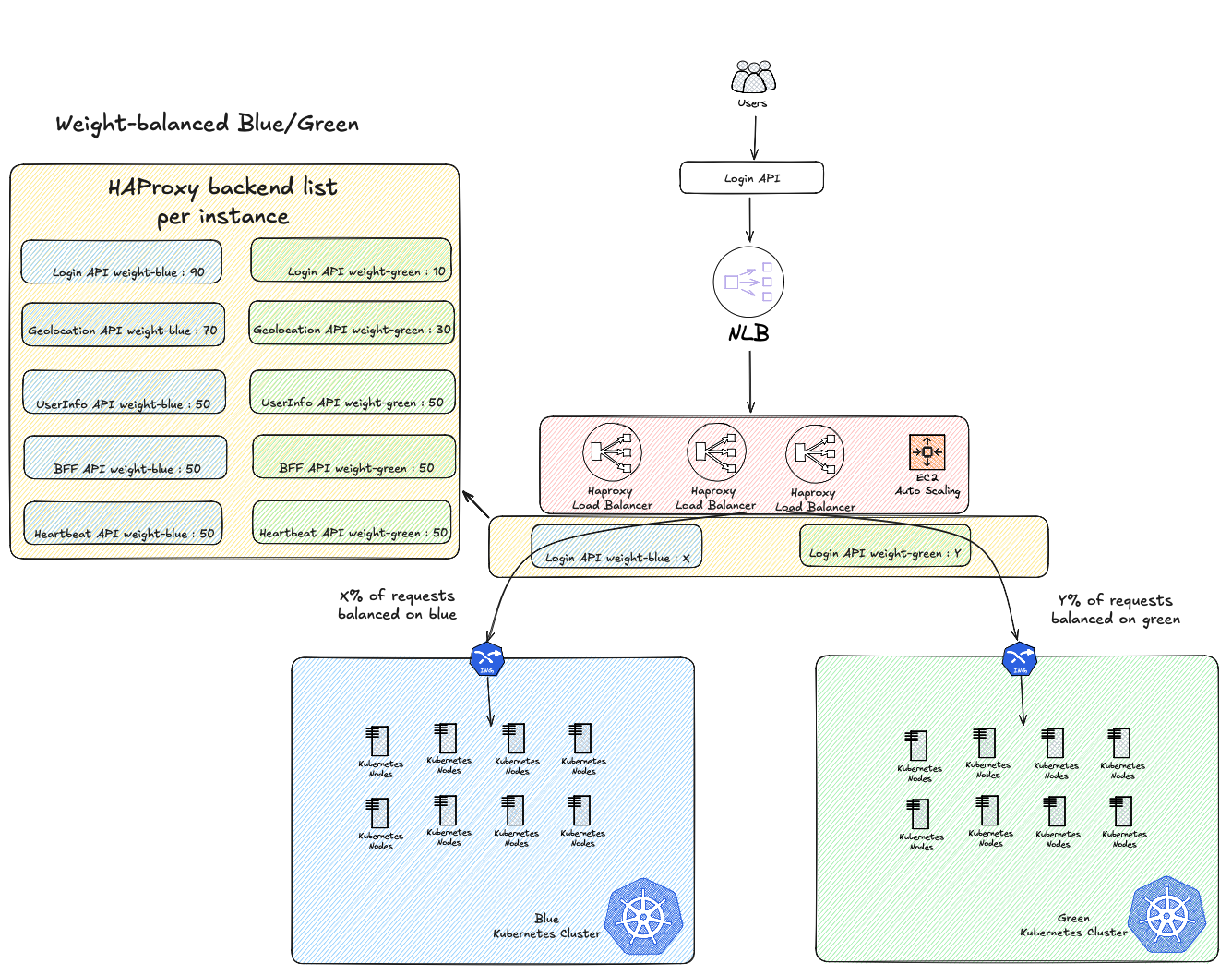
In this architecture, each API is represented as an HAProxy backend with configurable weights that control traffic distribution between the blue and green clusters. By adjusting these backend weights, we can progressively increase traffic to the new cluster or instantly rollback if needed with a simple update of our Terraform state.
Importantly, this load balancing layer added negligible latency to our response times, giving us confidence to proceed.
Deploying and synchronizing applications on both clusters
A critical challenge in our migration strategy was ensuring application parity between clusters. Without a centralized orchestration tool to manage deployments across all environments globally, we needed to adapt our existing processes.
At Bedrock, we use a common CI/CD workflow shared by all development teams to build and deploy their applications to Kubernetes. Our first step was updating this workflow to deploy applications to both clusters simultaneously. This ensured that all workloads remained synchronized between blue and green environments at all times.
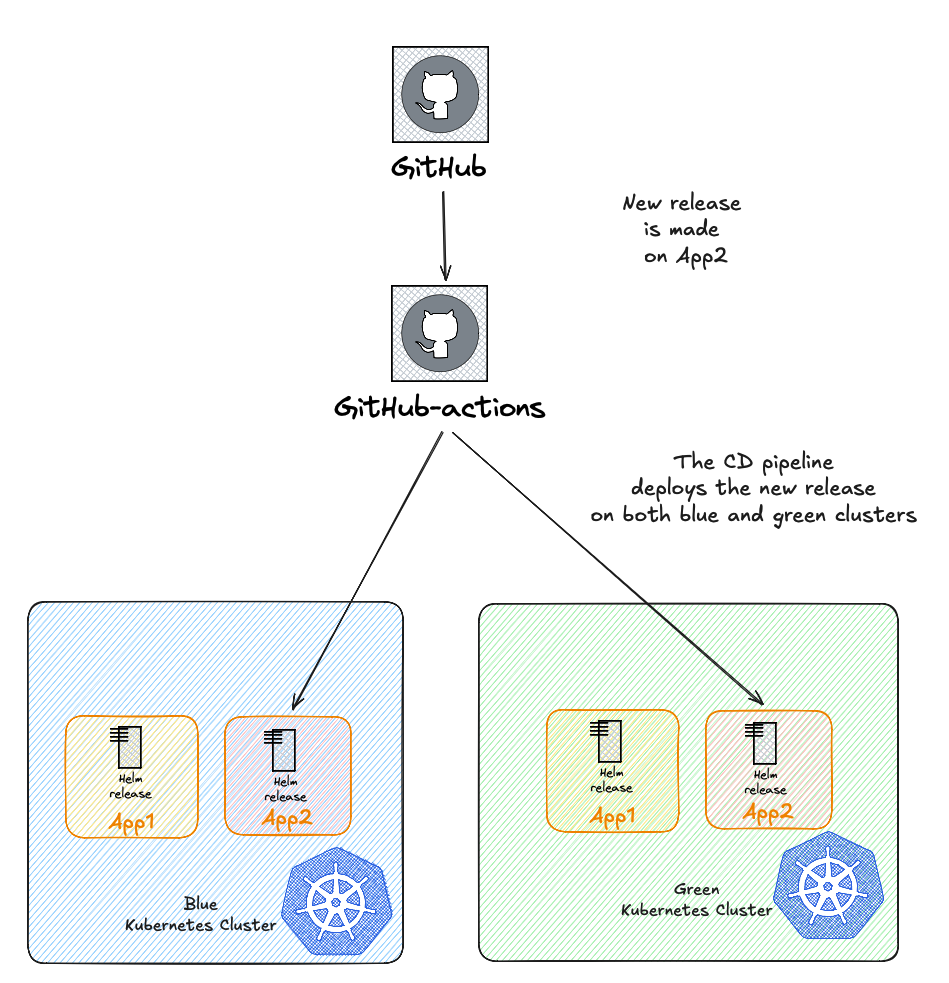
However, not all projects follow the same deployment cadence. Some applications are rarely redeployed, which meant we couldn’t rely solely on the CI/CD pipeline to synchronize everything. We had to manually verify that all projects were deployed and ready to receive traffic on both clusters before proceeding with traffic shifting.
This manual overhead highlighted the need for a more automated approach. To address this, we introduced a specific annotation to our Helm releases. This annotation is consumed by a workflow we developed, which can automatically redeploy releases from one cluster to another. This would significantly accelerates synchronization and will prove invaluable for any future blue/green migrations—whether for CNI changes, Kubernetes upgrades, or other infrastructure evolutions.
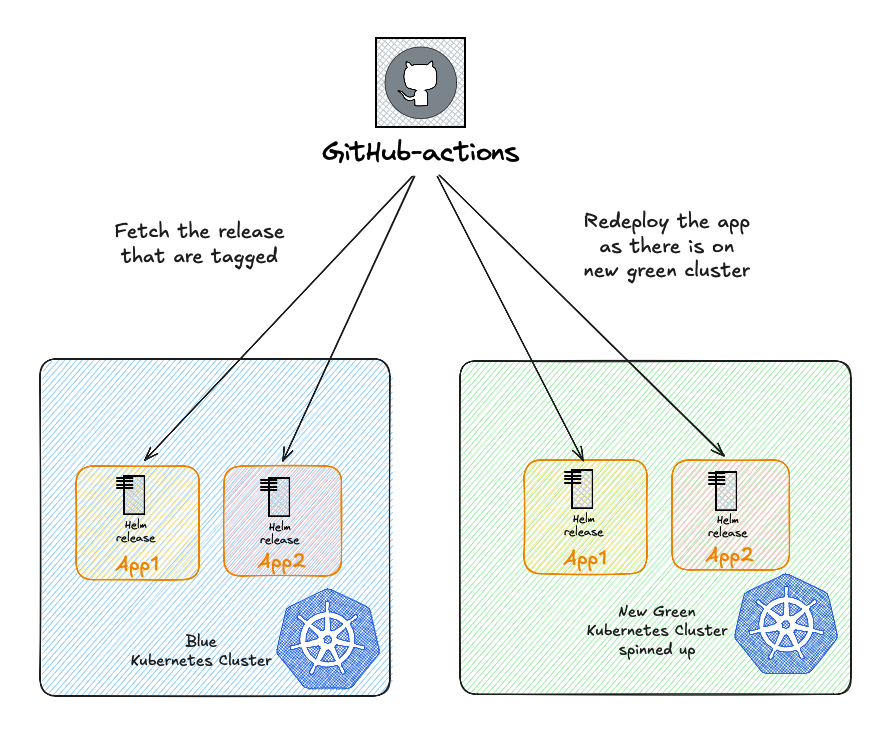
Consul powered configuration update
But how do you update weights on the fly to advance the migration or rollback during issues?
We leverage Consul to dynamically update our HAProxy configuration. Using Consul-agent and Consul KV/Store, we synchronize all HAProxy configurations across our infrastructure:
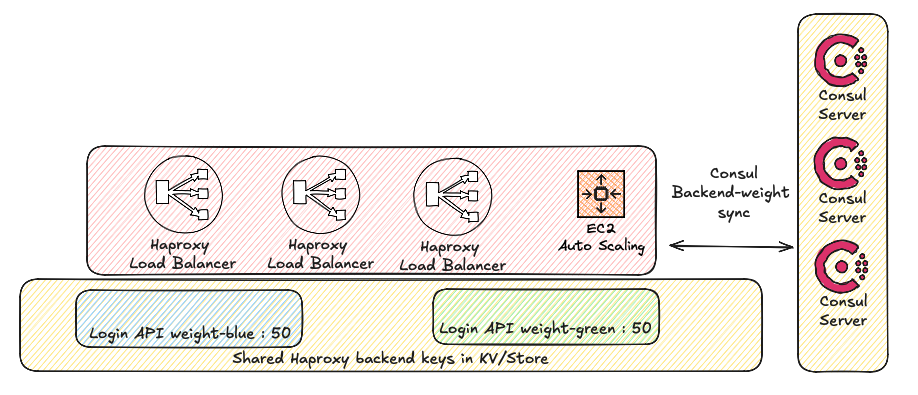
When ready to migrate an application, we simply update the blue and green weights for that specific API in our Consul KV/Store. The Consul-template opens a persistent connection to the Consul server KV/Store and detects the change to its watched keys and triggers a hot reload of HAProxy via the Runtime API, seamlessly shifting traffic distribution. Using the Runtime API saves us the need to execute HAProxy reload which could cause some loss of performance during high traffic events, same approach we use for our HSDO project.
Conclusion
So to recap, here’s how we achieved our zero-downtime migration from VPC CNI to Cilium:
- Deployed a new Kubernetes cluster with Cilium as the CNI, running in parallel to our existing VPC CNI cluster
- Set up HAProxy as a traffic orchestrator in front of both clusters, with configurable weights to control traffic distribution
- Leveraged Consul KV/Store to manage HAProxy configuration dynamically, allowing us to adjust traffic weights on the fly
- Gradually shifted traffic from the blue (VPC CNI) cluster to the green (Cilium) cluster, application by application
- Monitored KPIs closely at each step to validate performance improvements and catch any potential issues early
- Maintained rollback capability throughout the process by simply adjusting weights back to the blue cluster if needed
This hybrid approach enabled us to migrate production workloads without service disruption while unlocking all the benefits of eBPF-powered networking.
One significant advantage of this architecture is its reusability. The same HAProxy and Consul-based traffic orchestration can be leveraged for future infrastructure changes—such as upgrading to new Kubernetes versions. While we currently perform in-place upgrades, major version upgrades can be risky. With this pattern already in place, we can simply spin up a new cluster with the target Kubernetes version and progressively migrate traffic, significantly reducing the risk associated with potentially breaking changes.
Potential enhancements to our solution include:
- Automate weight adjustments based on real-time metrics leveraging our monitoring stack Victoria Metrics
- Implement automated rollback triggers if error rates or latency thresholds are exceeded
- Create a self-service interface for teams to control their own application migrations
- Target specific subsets of users and enable sticky canaries, which will ensure that a subset of users are always redirected to our new cluster
Many thanks to all contributors, reviewers of this article and people who worked on this project, and especially to our beloved Lead at the time: Vincent Gallissot