
Retour à l’AWS Summit
Deux années se sont écoulées depuis le dernier AWS Summit à Paris, il a fait son retour ce 12 avril !
Cet évènement, qui a lieu au printemps dans plusieurs pays, est l’occasion de rencontrer la communauté AWS française, d’assister à de nombreuses conférences et de bénéficier de retours d’expérience d’autres clients.
C’était aussi pour nous, comme en 2019, l’occasion de partager les nôtres !
Depuis notre migration vers le Cloud, AWS et Kubernetes entre 2018 et 2021 (plus d’informations dans Le Plan Copenhague), nous sommes plusieurs centaines à travailler au quotidien avec AWS.
Cette année, cinq de nos DevOps, SysOps et Développeurs ont eu la chance de se rendre à l’AWS Summit.
Nous partageons quelques notes que nous avons prises lors de cette journée, sur des sujets qui nous ont marqués et qui vont sans doute nous occuper une partie de l’année à venir.
Sommaire
- Retour à l’AWS Summit
- Rendez vos équipes de Data Science 10x plus productives avec SageMaker
- Comment le cloud permet à France Télévisions d’innover dans la diffusion de contenu live
- Découvrez comment Treezor utilise AWS comme moteur de sa plateforme de Banking-as-a-service
- Tracer votre chemin vers le Modern DevOps en utilisant les services AWS d’apprentissage machine
- Innover plus rapidement en choisissant le bon service de stockage dans le cloud
- Sécuriser vos données et optimiser leurs coûts de stockage avec Amazon S3
- Minimiser vos efforts pour déployer et administrer vos cluster Kubernetes
- Serverless et évènement, les nouvelles architectures
- Nous étions aussi intervenants
- Conclusion de l’article
Rendez vos équipes de Data Science 10x plus productives avec SageMaker
Conférence présentée par :
- Olivier Sutter - AWS Solution Architect
- Yoann Grondin - IA Team Leader Canal+

Cette conférence présentait le produit Amazon SageMaker, d’abord dans sa globalité, puis appliqué au cas des équipes de Data Scientist chez Canal+.
SageMaker a été lancé fin 2017 pour créer, entraîner et déployer des modèles de machine learning. C’est une solution tout-en-un, avec une interface graphique intuitive et un accent porté sur l’automatisation. Amazon promet également de gagner en performance sur SageMaker via l’implémentation de nombreux algorithmes d’apprentissage supervisés ou non-supervisés (XGBoost, kNN, PCA…).
De manière générale, les équipes de Canal+ utilisent des solutions d’apprentissage pour différents cas d’usages :
- Personnaliser l’expérience utilisateur et proposer du contenu ciblé
- Mieux connaître, labelliser, classifier leurs contenus vidéo
- Anticiper les besoins des abonnés ou des prospects
Ils se sont tournés vers SageMaker pour diminuer le temps passé dans les étapes de preprocessing, data cleaning et déploiement en production.
Chez Bedrock, nous avons aussi rencontré ces problématiques, nous avons réalisé des PoC de différentes solutions (dont SageMaker) et nous avons retenu la plateforme Databricks.
En effet, Databricks répond à nos besoins de fine-tuning des paramètres des clusters Spark et d’intégration avec Terraform (ce qui est important pour nous car nous utilisons exclusivement de l’Infra-as-Code). Nous avons également automatisé le déploiement en production de nos modèles d’apprentissage, de la même manière que SageMaker.
Cette conférence nous a conforté dans l’approche et l’utilisation que nous avons de nos outils actuels, tout en nous confrontant à d’autres solutions techniques et d’autres cas d’usages au sein de notre industrie.
Résumé par Gabriel FORIEN - DevOps
Comment le cloud permet à France Télévisions d’innover dans la diffusion de contenu live
Conférence présentée par :
- Raphaël Goldwaser - AWS Solution Architect
- Guillaume Postaire - Directeur de la Media Factory, France Télévisions
- Matthieu Parmentier - Responsable de l’Al factory, France Télévisions
- Nicolas Pierre - Al factory Lead Tech, France Télévisions
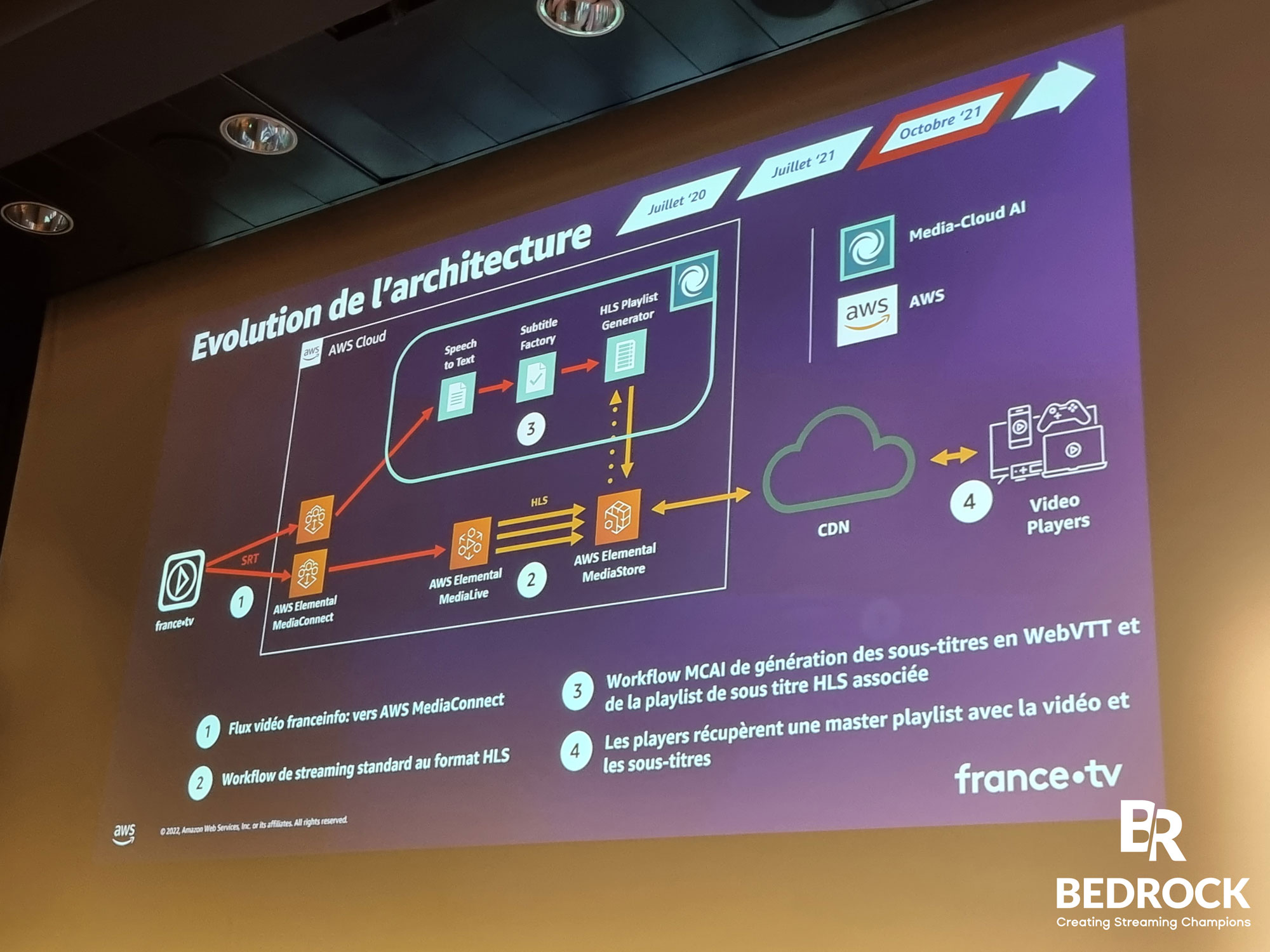
Nous avons assisté à une conférence présentée par les responsables Média et AI de France Télévisions et Raphaël Goldwaser Solutions Architect chez AWS. Ils nous ont parlé de l’évolution de leur usage du cloud dans la diffusion de vidéo en direct et des différentes étapes de la construction d’un système de sous-titrage automatique en direct.
Pour ce système de sous-titrage, ils utilisent les services Media & Entertainment fournis par AWS.
Les flux vidéo sont envoyés directement dans le cloud via Elemental MediaConnect pour générer des sous-titres automatiquement en utilisant Media-Cloud AI et Speechmatics. Une fois les fichiers de sous-titres générés, ils sont insérés et synchronisés sur le flux en direct.
Ces outils peuvent également être utilisés pour analyser des vidéos afin de contextualiser les publicités affichées et/ou choisir le meilleur moment pour les afficher.
Chez Bedrock comme chez France Télévisions, nous challengeons régulièrement les solutions Médias proposées par AWS pour améliorer nos infrastructures et apporter de nouvelles fonctionnalités à nos produits.
Résumé par Christian VAN DER ZWAARD - SysOps
Découvrez comment Treezor utilise AWS comme moteur de sa plateforme de Banking-as-a-service
Conférence présentée par :
- Armel Negret - AWS Central Sales Representative
- Nicolas Bordes - Technical Lead and AWS Sponsor, Société Générale
Treezor, une filiale du groupe Société Générale, fournit une plateforme complètement APIsée qui permet aux fintechs et plus généralement aux acteurs de la finance d’accéder à leurs services bancaires. Cette plateforme est hébergée sur AWS et utilise une stack de services entièrement serverless : API Gateway, CloudWatch, Lambda, SNS et SQS entre autres. Les Lambdas sont développées en PHP grâce au framework Bref.
A l’instar de Treezor, Bedrock possède également de nombreuses Lambda développées en PHP avec Bref. Ces Lambdas sont majoritairement déployées via le framework serverless et maintenues par le pôle backend. Au pôle infrastructure, nous essayons d’utiliser d’autres langages comme Python ou Go avec lesquels nous sommes plus à l’aise et qui sont nativement supportés par Lambda.
L’approche “full serverless” est intéressante car elle permet de s’abstraire de la gestion de l’infrastructure sous-jacente et donc de se concentrer sur des problématiques intrinsèques au métier.
En sus, les services AWS serverless apportent souvent nativement de la haute disponibilité ainsi que de l’auto-scaling, deux problématiques très importantes pour garantir un service de qualité à nos utilisateurs finaux. C’est pour ces raisons que Bedrock utilise de nombreux services AWS serverless : Athena, CloudWatch, DynamoDB, Lambda, S3, SNS, SQS, Kinesis, …
Le pôle infrastructure de Bedrock étant relativement “petit” par rapport au nombre total de développeurs (23 devops/sysops pour 250 fullstack en date du 15 avril 2022), l’utilisation du serverless est un réel enjeu business.
Serverless ne répond pas à tous les besoins non plus, particulièrement sur de très forts pics de charge où nous préférons utiliser Kubernetes.
Résumé par Timothée AUFORT - DevOps
Tracer votre chemin vers le Modern DevOps en utilisant les services AWS d’apprentissage machine
Conférence présentée par :
- Patrick Lamplé - AWS Principal Specialist SA
La conférence nous proposait d’en apprendre un peu plus sur les nouveaux produits AWS Code Guru et DevOps Guru.
Code Guru se découpe en deux parties :
- Reviewer, qui a pour ambition d’accélérer la revue de code ;
- Profiler, qui peut aider à optimiser les performances d’une application. A ce jour, ces services ne supportent que les langages Python et Java.
DevOps Guru
permet d’identifier les comportements anormaux des applications au runtime.
Par exemple, si une application utilise une table DynamoDB qui n’est pas suffisamment provisionnée, une alerte va être déclenchée. Cette dernière pourrait permettre d’identifier un souci de configuration avant même que l’application ne soit déployée en production.
Chez Bedrock, les langages utilisés étant principalement Javascript, PHP et Python, Code Guru ne sera pas une solution adéquate dans toutes les situations. Nous avons donc mis en place la solution KICS qui nous permet, à l’aide de règles Open Policy Agent, d’effectuer automatiquement de nombreuses validations sur le code infrastructure (Terraform, Docker, YAML, …). KICS est utilisé au travers de GitHub Actions pour ajouter des commentaires sur les pull requests comme Code Guru est capable de le faire.
Une analyse au runtime effectuée par DevOps Guru pourrait permettre de venir compléter la liste de services AWS que nous utilisons déjà et qui vérifient la configuration de notre infrastructure comme : Config, Trusted Advisor, CloudWatch, …
Les outils du Modern DevOps d’AWS pourraient venir en complément d’outils de qualité actuellement utilisés chez nous. À tester en complément de KICS pendant une de nos journées R&D (journées organisées le dernier vendredi du mois, un mois sur deux).
Résumé par Valentin CHABRIER & Mickaël VILLERS - DevOps
Innover plus rapidement en choisissant le bon service de stockage dans le cloud
Conférence présentée par :
- Thomas Barandon - AWS Enterprise Support Manager
- Laurent Dirson - Directeur des Solutions Business et des Technologies, Nexity
Thomas Barandon a rappelé les solutions de stockage d’AWS : S3 pour du stockage objet, EBS pour le stockage bloc et EFS/FSx pour le stockage fichier. Il a par la suite présenté Storage Gateway, qui permet d’utiliser les services de stockage AWS dans une infrastructure on-prem via un montage NFS/Samba ou iSCSI.
Laurent Dirson de chez Nexity a ensuite partagé la stratégie adoptée pour concevoir leur SI comme un service. Tous leurs documents sont désormais stockés dans un bucket S3 mis à disposition des agences via un montage NFS opéré par l’outil Storage Gateway. Une politique d’Object Lock permet d’utiliser le modèle WORM (write-once-read-many).
Chez Bedrock, nous stockons déjà la grande majorité de nos données dans des buckets S3. Nous aimerions aussi bénéficier des avantages de ce service pour le stockage de nos métriques. Mais, comme nous utilisons VictoriaMetrics, ce mode de stockage n’est pas disponible et ces données sont stockées dans EBS. Peut-être que Storage Gateway nous permettrait d’écrire nos métriques directement sur un bucket S3 ?
Résumé par Coraline PETIT - SysOps
Sécuriser vos données et optimiser leurs coûts de stockage avec Amazon S3
Conférence présentée par :
- Meriem Belhadj - AWS Storage Specialist Solutions Architect
Pendant cette présentation, Meriem Belhadj est revenue sur les classes de stockage disponibles sur S3, en mettant une attention particulière à Glacier Instant Retrieval et à Intelligent-Tiering. Le second permet d’appliquer une politique de stockage basée sur la fréquence d’accès aux données au cours des 30 derniers jours.
En effet, pour déterminer la “bonne” classe à utiliser, il faut notamment connaître la disponibilité des données. Les autres points à prendre en compte sont la fréquence d’accès, les performances recherchées, la taille des objets à stocker et enfin la durée de rétention.
Nous appliquons ces pratiques chez Bedrock depuis plusieurs années. Toutefois, il serait judicieux de mettre en place des règles, type AWS Config, pour s’assurer que ces recommandations soient bien appliquées sur tous nos buckets S3.
Résumé par Coraline PETIT - SysOps
Minimiser vos efforts pour déployer et administrer vos cluster Kubernetes
Conférence présentée par :
- Abass Safouatou - AWS Lead Solution Architect
- Sébastien Allamand - AWS Solution Architect Specialist Container
- Patrick Chatain - CTO Contentsquare
Contentsquare, analyste de l’expérience numérique, est venu nous parler de son utilisation d’EKS Blueprint avec AWS CDK (Cloud Development Kit) pour la configuration et le déploiement de leurs infrastructures Kubernetes. Cet outil leur a permis de rapidement migrer leurs infrastructures dans le Cloud.
À l’occasion de cette conférence, un début de comparatif a été amorcé entre les solutions de passage à l’échelle automatique : Cluster Autoscaler et Karpenter.
Cette analyse a particulièrement attiré notre attention : nous souhaitons migrer nos clusters Kubernetes, actuellement déployé par Kops vers des clusters EKS, pour gagner en maintenabilité et en rapidité de scaling. Karpenter est l’une des solutions que nous étudions dans le cadre de ce projet, afin de tirer partie de cet outil qui a été développé par AWS et qui semble mieux tirer profit des fonctionnalités spécifiques d’AWS que Cluster Autoscaler.
Contentsquare a mentionné son besoin de développer un outil de passage à l’échelle basé non pas sur la consommation CPU et mémoire mais sur des métriques custom. C’est un besoin que nous avons également chez Bedrock, nous avons donc développé un outil pour y répondre, vous trouverez plus de détails dans l’article de blog dédié à cet outil. Cette remarque nous a conforté dans notre volonté de continuer à open-sourcer les outils que nous développons, pour qu’ils bénéficient à la communauté.
Résumé par Coraline PETIT & Christian VAN DER ZWAARD - SysOps
Serverless et évènement, les nouvelles architectures
Mainframe, monolithe, système distribué, microservices, la conception d’un SI ou d’un projet est en constante évolution.
Ceci dit, depuis plusieurs années, beaucoup d’entreprises font la transition sur des architectures orientées évènements pour limiter les couplages forts entre les microservices.
À cela s’ajoute l’essor du tout Serverless : fini le temps où on gérait nous-mêmes le dimensionnement de nos serveurs.
Cette année, plusieurs conférences étaient consacrées à ces sujets.
3 designs patterns pour bien démarrer avec Serverless
Matthieu Napoli, Hero AWS Serverless et créateur de la librairie Bref, a présenté trois designs patterns pour bien démarrer avec Serverless.
Application HTTP
Il est maintenant très simple et peu coûteux de créer des applications HTTP en Serverless, en combinant différents services AWS :
- Lambda function et Lambda function URL (nouvelle fonctionnalité sortie une semaine avant le Summit) ;
- CloudFront CDN ;
- API Gateway ;
- S3.
Un exemple concret :
- CloudFront CDN délivre les assets JS/CSS/image depuis S3 ;
- il transmet également les retours d’API Gateway ;
- et API Gateway communique avec la/les Lambdas.
Ajoutons une base de données DynamoDB ou Aurora et nous voilà avec une application full Serverless.
File de messages avec worker
Lorsqu’on met en place ce type de pattern, nous déployons :
- un projet qui pousse un message dans une file “producer” ;
- une file de messages (SQS/SNS/MQ) ;
- un second projet qui lit les messages depuis la file “consumer”.
Dans cette architecture, le “consumer” se connecte à la file de messages, lit les messages et se charge de toute la gestion d’erreur et de retry.
En utilisant une Lambda comme “consumer”, AWS a mis en place une intégration spécifique entre les files de messages et les Lambdas. C’est maintenant la file de messages qui appelle directement la Lambda en lui donnant le message et qui gère également le retry : votre code applicatif est déchargé d’autant de responsabilités sans valeur métier.
Communication entre microservices
Quoi de plus contraignant que de gérer la communication de plusieurs services ? Il faut gérer :
- les erreurs : que faire si plusieurs microservices partent en timeout ou échouent dans un workflow ?
- le couplage : lors de la création d’un nouveau microservice, il doit être lui aussi appelé dans les chaines d’appels ;
- l’authentification entre les différents services ;
- et la latence : les appels de services en cascade augmentent la durée totale d’exécution.
De ce constat, Matthieu propose une solution que nous avons déjà mise en place chez Bedrock depuis plusieurs années : communiquer avec des évènements.
Pour cela, AWS fournit EventBridge : un service serverless de routage d’évènements sans stockage.
Ainsi, si un microservice doit en informer d’autres, il lui suffit d’envoyer un événement dans EventBridge. Les autres services n’auront qu’à “écouter” l’événement.
SNS, plus ancien, permettait la même approche, mais EventBridge propose de créer des règles de filtrage sur la totalité du message d’un événement.
Construire des applications serverless orientées événements
Nicolas Moutschen, Solution Architect AWS et Guillaume Lannebere de chez Betclic ont fait un retour d’expérience sur la mise en place de différents services serverless AWS orientés événements.
Betclic absorbe à chaque match/course, une quantité énorme de données (plusieurs millions d’événements) en quelques minutes. Par exemple, lors d’un match de football, les paris sont effectués à tout instant : avant le match, à la mi-temps, dans les dernières minutes… Leur SI est donc soumis, fréquemment, à de très forts pics de charge pendant des laps de temps très courts.
Afin d’éviter de provisionner énormément de machines pour se mettre à l’échelle, Betclic à fait le choix du full serverless. Les applications de paris et de paiement communiquent par des messages d’événements envoyés dans le service AWS SNS : les Lambdas reçoivent les messages et les traitent avec une mise à l’échelle quasi immédiate en fonction du trafic.
Résumé par Fabien LALANNE - Développeur
Nous étions aussi intervenants
Nous aimons tout particulièrement apprendre en lisant des articles écrits par d’autres membres de notre communauté ou en assistant à des conférences présentées par d’autres clients. Il est donc normal et important pour nous, de partager aussi notre expérience, ce que nous faisons régulièrement, y compris sur ce blog.
Cette année, nous avons eu la chance d’intervenir et de partager avec notre communauté lors de trois conférences. Merci à AWS pour la confiance qui nous a été accordée !
Transformer le load balancing pour optimiser le cache : objectif 50 millions d’utilisateurs
Vincent Gallissot @vgallissot, Lead Cloud Architect, a expliqué comment Bedrock a amélioré le Load Balancing chez AWS, pour optimiser le cache de sa diffusion de vidéos, avec comme objectif 50 million d’utilisateurs :
Démarrage des conférences à l’#AWSSummit. Et voici un REX intéressant pour partager l’une des problématiques intéressantes pic.twitter.com/kuKGZZyE2A
— Akram BLOUZA (@akram_Blouza) April 12, 2022
Guillaume Marchand, Senior Solutions Architect chez AWS a débuté notre talk en parlant de Load Balancing chez AWS, des différentes solutions et des bonnes pratiques, ainsi que des exemples d’architectures possibles. J’ai ensuite expliqué notre besoin de scaler des serveurs de cache et comment nous avons relevé ce challenge, en développant notamment Haproxy Service Discovery Orchestrator. Ce talk n’a pas été enregistré, mais les slides sont disponibles sur ce lien.
Etes-vous bien architecturé ?
Pascal Martin @pascal_martin, Principal Engineer, est intervenu pour partager notre retour d’expérience client pendant une conférence de présentation du Well-Architected Framework :
Pour cette conférence, Rémi Retureau, Partner Management SA Lead chez AWS, a commencé par présenter les pratiques Well-Architected. Un ensemble de recommandations basées sur 10 ans d’expertise de Solutions Architects AWS.
Je suis ensuite intervenu pour partager un retour d’expérience : comment nous utilisons Well-Architected Framework chez Bedrock pour nous aider à valider l’architecture de composants de notre plateforme, à prioriser des évolutions ou même, à en identifier de nouvelles.
En quelques mots : nous passons une revue Well-Architected une fois par an et, si nous ne nous posons pas explicitement l’ensemble des questions du Framework à chaque nouveau projet, nous l’intégrons de plus en plus à nos pratiques et habitudes.
Si vous commencez à travailler sur AWS, le Well-Architected Framework et ses recommandations, bien que peut-être effrayantes au premier abord, sont un ensemble de bonnes pratiques qui vous aideront à concevoir et à construire une plateforme plus solide, plus résiliente et moins coûteuse.
Préparez et donnez votre premier talk
Pascal est aussi intervenu, cette fois en tant qu’AWS Hero pour guider la préparation de vos talks :
Pour cette seconde intervention, j’ai choisi de parler d’un sujet qui n’est pas lié à AWS. J’aime assister à des conférences : je le fais depuis très longtemps et j’apprends beaucoup ainsi. Je suis aussi toujours très content de voir d’autres speakers monter sur scène et partager leur expérience. Je sais que beaucoup de personnes, dans notre communauté, ont des connaissances et des idées géniales et j’aimerais qu’elles les partagent plus souvent !
Je sais toutefois que cet exercice est effrayant et que se lancer sur scène pour la première fois est difficile. J’espérais donc, à travers ce talk déjà donné chez Bedrock lors d’un Last Friday Talks (une journée de conférences internes le dernier vendredi du mois, un mois sur deux) aider de nouvelles personnes à se lancer. L’idée vous intéresse mais vous n’avez pas pu assister à cette conférence ? Et bien, j’ai aussi écrit un livre pour vous accompagner : « Préparez et donnez votre première conférence (quand ce n’est pas votre métier) » Et j’ai hâte, l’année prochaine, de vous voir monter sur scène et partager avec notre communauté !
Conclusion de l’article
Avec des milliers de participants et participantes, l’AWS Summit est toujours une excellente occasion d’échanger et d’apprendre. Nous étions également très heureux de pouvoir, cette année encore, partager notre expérience lors de trois interventions.
Cet événement était aussi le premier pour certains et certaines d’entre nous, une très bonne découverte !
Comme beaucoup d’autres speakers et entreprises rencontrés mardi, nous recrutons : des SysOps, des DevOps, des développeurs et des développeuses, une ou un FinOps. Vous voulez nous aider à construire et à faire grandir notre plateforme ? Nous avons encore de super projets et challenges, faites-nous signe !