To value our data in order to understand better our service and improve it, we use Spark. You can find more information in a recent article about our datalake. We recently migrated our biggest project from Spark 1.5 to Spark 2.2 and wanted to share that story.
Spark 2 has been released a year ago (July 26, 2016). Maybe we are a bit late, but better late than never.
We are working with an official version from Cloudera with Spark 1.6 as the default version.
Our project runs everyday to get data from different sources and send them to different destinations.
It is built with Java and Spark 1.5, but we encountered several problems with those technologies. First of all, the Java + Spark community is smaller than the ones for Python or Scala. Secondly, the Spark 1.5 community is also smaller than the one of version 2.2.
That sometimes made information hard to find.
But most of all, we did not succeed to integrate new components that work with more recent versions.
We wanted to migrate for bugs fixes in general and in a performance purpose too.
I) Workflow

a) Spark 1.5 to Spark 1.6
First, we had decided to migrate to 1.6 to do a progressive migration. But we bumped into a bug with a UDF. We had difficulties fixing it, and it was resolved in 2.2.
We finally decided to migrate directly to 2.2.
b) First validation with unit tests
We did the migration and ran our unit tests to see and fix the problems.
c) Functional tests
Then, we ran our jobs with some data sets. The idea was to check the differences with Spark 1.5.
We wanted to be sure that our unit parts were working together.
d) Double run
Then, we set out for a double run. It means that we had our jobs running both with Spark 1.5 and Spark 2.2 and we compared the outputs each day.
We used Airflow to deal with that. If you know Airflow, you will understand that we added a new DAG to run our project with Spark 2.2.
The idea was to see the potential differences between the two on a daily basis.
At the end, we merged our branch into master.
2) Changes to migrate to 2.2
There are different changes from Spark 1.5 to 1.6 to 2.2. You will find them described in the documentation.
The idea here is to focus on the problems we met, the noticeable changes for us and how we dealt with them.
a) Dataset
Of course, the main change is that “dataFrame” does not exist anymore. You must replace it by “Dataset<Row>”.
Actually, “DataFrame” and “Dataset” were unified with Spark 2.0. In reality, for untyped API like Python, “DataFrame” still exists. But, we work with Java.
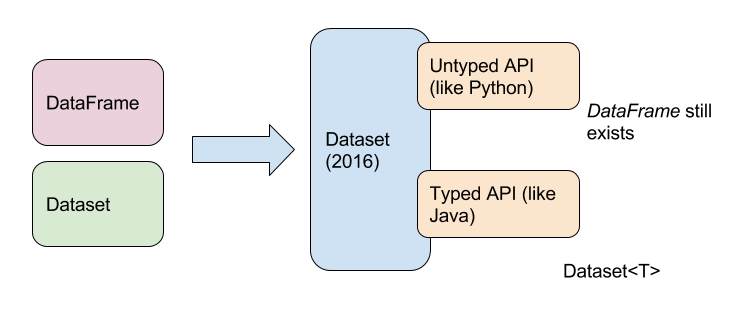
Using “Dataset<T>” is a way to apply a schema at the compilation. If there is a problem, you will get a logical exception. Before, with “DataFrame”, you could only have runtime exceptions.
As a first step, we replaced “DataFrame” by “Dataset<Row>”
b) SparkSession
A second major difference is “SparkSession”. It is the new entry to Spark. There is no need anymore to create a “SparkConf”, a “SparkContext” and a “SQLContext”. It is possible to get all of it just with a “SparkSession”.
But, it is important to understand that if you just want to migrate your code in a first step to get it work with Spark 2, it is not a need to use “SparkSession”. “SparkConf”, “SparkContext” and “SQLContext” still work.
That is what we decided to do.
c) Iterable to Iterator
The return type “Iterable” is incompatible with “PairFlatMapFunction”. We had to replace “Iterable<>” with “Iterator<>”.
We replaced code like that:
public Iterable<String> call(String s) throws Exception {
...
return list;
}
by something like that:
public Iterator<String> call(String s) throws Exception {
...
return list.iterator();
}
d) Creating a UDF using hiveContext is not possible anymore the same way
Before, you could do something like that :
hiveContext.sql("CREATE TEMPORARY FUNCTION function AS ...")
But now, you have to enable hive support first. You must do it with the SparkSession:
SparkSession spark = SparkSession
.builder()
.appName("Java Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.enableHiveSupport()
.getOrCreate();
If “enableHiveSupport” is not enabled, there is an error like this :
java.lang.UnsupportedOperationException: Use sqlContext.udf.register(...) instead.
We decided not to use “SparkSession” in a first step and to follow the error instructions.
We replaced our direct call to Hive by a UDF registration.
e) Deprecations
We noticed some deprecations like HiveContext or Accumulators for instance. But we decided not to deal with them for the moment.
d) Performance
We have made some gains in performance. Before, running our jobs lasted around three hours. Now, it lasts around two and a half hours.
We hope we will make some other gains by migrating to the Spark 2.2 philosophy (“SparkSession”, etc).
Conclusion
As there are many backward compatibilities with Spark 2, it is not so difficult to make a first migration to make your project work. Nonetheless, it could be long to validate. It depends on your tests stategy too.
Our next step now will be to integrate the new philosophy of Spark 2.2 to get the best of the new version.
Nastasia Saby (Zenika consultant)